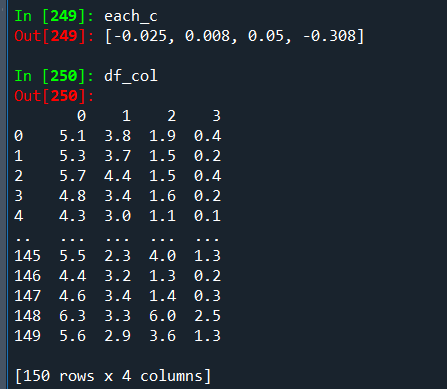
I have some troubles with my Python work,
my steps are:
1)add the list to ordinary Dataframe
2)delete the columns which is min in the list
my list is called 'each_c' and my ordinary Dataframe is called 'df_col'
I want it to become like this:
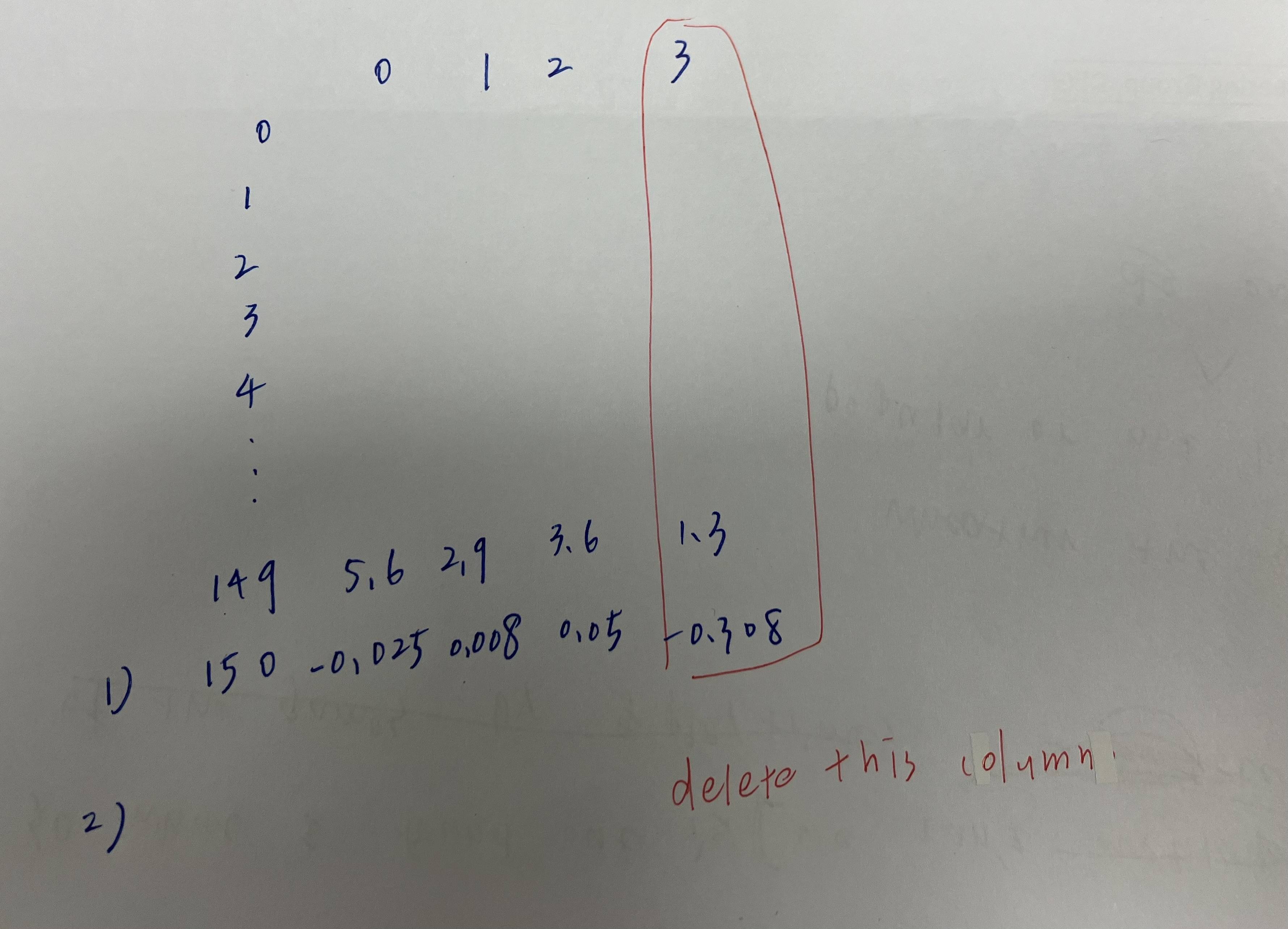
hope someone can help me, thanks!
CodePudding user response:
This is clearly described in the documentation: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop.html
df_col.drop(columns=[3])
CodePudding user response:
Convert each_c to Series, append by DataFrame.append and then get indices by minimal value by Series.idxmin and pass to drop - it remove only first minimal column:
s = pd.Series(each_c)
df = df.append(s, ignore_index=True).drop(s.idxmin(), axis=1)
If need remove all columns if multiple minimals:
each_c = [-0.025,0.008,-0.308,-0.308]
s = pd.Series(each_c)
df = pd.DataFrame(np.random.random((10,4)))
df = df.append(s, ignore_index=True)
df = df.loc[:, s.ne(s.min())]
print (df)
0 1
0 0.602312 0.641220
1 0.586233 0.634599
2 0.294047 0.339367
3 0.246470 0.546825
4 0.093003 0.375238
5 0.765421 0.605539
6 0.962440 0.990816
7 0.810420 0.943681
8 0.307483 0.170656
9 0.851870 0.460508
10 -0.025000 0.008000
EDIT: If solution raise error:
IndexError: Boolean index has wrong length:
it means there is no default columns name by range - 0,1,2,3. Possible solution is set index values in Series by rename:
each_c = [-0.025,0.008,-0.308,-0.308]
df = pd.DataFrame(np.random.random((10,4)), columns=list('abcd'))
s = pd.Series(each_c).rename(dict(enumerate(df.columns)))
df = df.append(s, ignore_index=True)
df = df.loc[:, s.ne(s.min())]
print (df)
a b
0 0.321498 0.327755
1 0.514713 0.575802
2 0.866681 0.301447
3 0.068989 0.140084
4 0.069780 0.979451
5 0.629282 0.606209
6 0.032888 0.204491
7 0.248555 0.338516
8 0.270608 0.731319
9 0.732802 0.911920
10 -0.025000 0.008000