I want to reshape my dataframe so I can pivot the 'kind' field, but I also want to include per-row aggregations.
df = pd.DataFrame([
{
'date': '2022-04-20',
'kind': 'alpha',
'scalar_a': 2,
'scalar_b': 5
},
{
'date': '2022-04-20',
'kind': 'bravo',
'scalar_a': 3,
'scalar_b': 7
},
{
'date': '2022-04-21',
'kind': 'charlie',
'scalar_a': 4,
'scalar_b': 3
},
{
'date': '2022-04-22',
'kind': 'bravo',
'scalar_a': 5,
'scalar_b': 1
},
])
This produces this table.
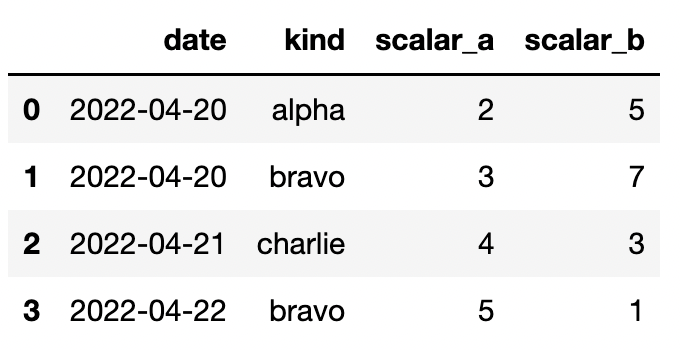
I want to reshape to this:
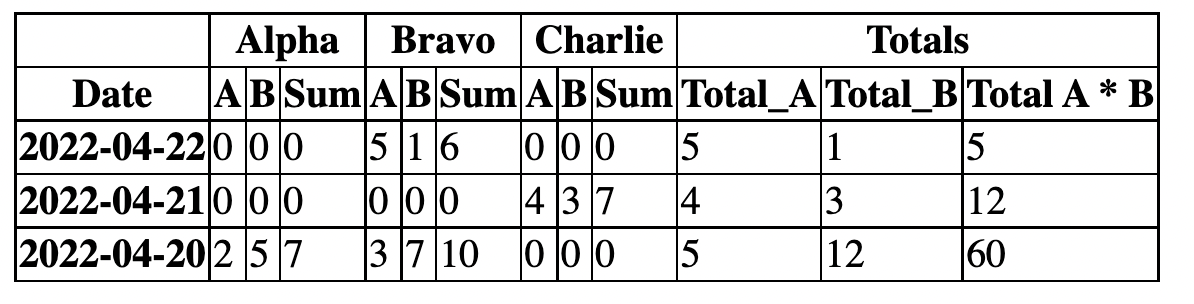
I want to:
- Aggregate my data by date, and have it reshaped so I can see each kind side-by-side.
- I want to compare Scalar_A and Scalar_B from each kinds on the same row, including a per-kind aggregation.
- I want to also have a totals column (per-row/ per-date)
My attempt was to create two dataframes (one for calculating the per-date totals, and another one to perform the pivot transformation), and then concatenate them across the horizontal axis.
totals_df = df.groupby('date').agg(
total_a=('scalar_a', 'sum'),
total_b=('scalar_b', 'sum'),
)
# I also need a column calculated by the aggregated fields.
totals_df["Total a*b"] = totals_df["total_a"] * totals_df["total_b"]
# Then I sort by descending date.
totals_df = totals_df.sort_values('date',ascending=False)

# And then to build my pivoted dataframe
pivot_df = df.pivot_table(
index=['date'],
columns=['kind'],
fill_value=0
)
# I attempt to invert the two top-level headers ([scalar_a, scalar_b] with [])
pivot_fundos = pivot_fundos.swaplevel(1,0, axis=1).sort_index(axis=1)
How would I proceed to include a per-date/per-kind aggregation? I want to include a column with scalar_a scalar_b for each kind sub-column.
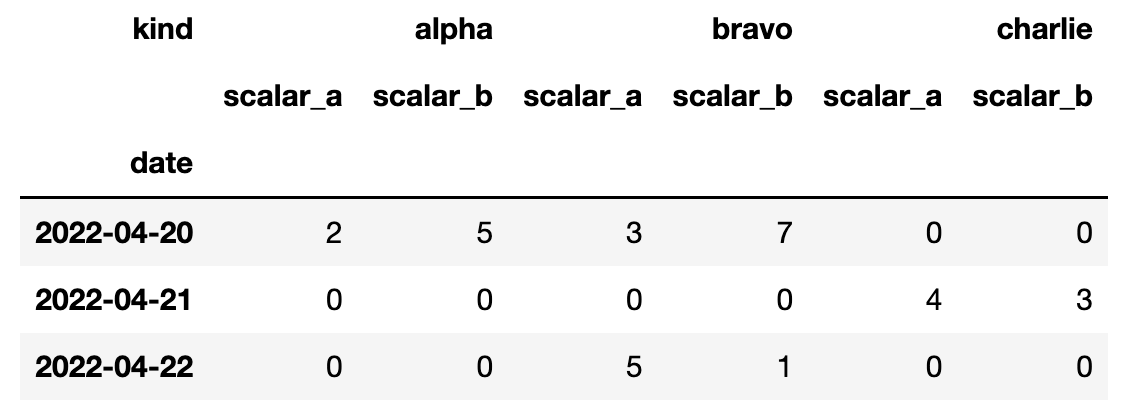
Then I concatenate both dataframes.
concatenated_dataframes = pd.concat([pivot_df, totals_df], axis=1)
The resulting dataframe doesn't have the "two-levels" headers I expected when calling the to_table() method. How do I fix that?

CodePudding user response:
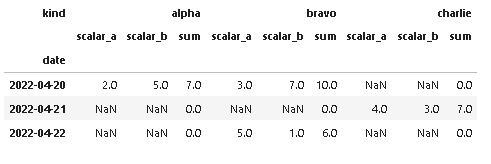
Use:
df2 = df.pivot(index='date', columns='kind', values=['scalar_a', 'scalar_b']).swaplevel(1,0, axis=1).sort_index(axis=1)
cols = [( x, 'sum') for x in df['kind'].unique()]
df2[cols]=df2.sum(axis=1, level=0).sort_index(axis = 1)
Output:
CodePudding user response:
I would approach it this way. First pivot_table, then use groupby on columns to compute the sums, finally concat everything (with inner concat to add the missing levels):
df2 = df.pivot_table(index='date', columns='kind',
values=['scalar_a', 'scalar_b'], fill_value=0)
df3 = (df2
.groupby(level=0, axis=1).sum().add_prefix('total_')
.assign(**{'Total a*b': lambda d: d.prod(1)})
)
out = pd.concat(
[df2.swaplevel(axis=1),
pd.concat({'sum': df2.groupby(level=1, axis=1).sum()}, axis=1)
.swaplevel(axis=1),
pd.concat({'Totals': df3}, axis=1),
], axis=1).sort_index(axis=1)
output:
kind Totals alpha bravo charlie
Total a*b total_scalar_a total_scalar_b scalar_a scalar_b sum scalar_a scalar_b sum scalar_a scalar_b sum
date
2022-04-20 60 5 12 2 5 7 3 7 10 0 0 0
2022-04-21 12 4 3 0 0 0 0 0 0 4 3 7
2022-04-22 5 5 1 0 0 0 5 1 6 0 0 0