I have a database of (changed items/data) grocery story aisles and products, and I'm trying to find the top 3 most expensive items in each aisle that are in stock.
My code for big query is this:
SELECT ROW_NUMBER() OVER (PARTITION BY aisle ORDER BY price DESC) AS high_prices, aisle,
price, product FROM `a_database.shopping.grocery_stores`
WHERE in_stock = TRUE AND high_prices <= 3
GROUP BY aisle
ORDER BY price;
I am receiving an error of: unrecognized name: high_prices at [2:30] due to the high_prices <= 3, however, I don't know another approach to this.
I am expecting an output of the 4 most expensive items by aisle in the store that are in stock, as said. but it doesn't work due to above error. When I remove high_prices <= 3, instead I'm getting a list of all items in the store along with their aisles completely out of order.
The expected output is similar to this screenshot:
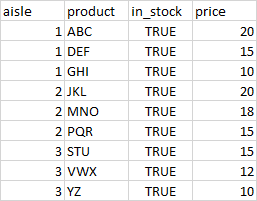
I have included a sample data table:
aisle product in_stock price
1 fresh_chicken TRUE 10
2 frozen_fish TRUE 10
3 truffles TRUE 15
2 cereal TRUE 5
2 cake TRUE 25
3 wine TRUE 30
1 fresh_fish TRUE 15
1 fresh_beef TRUE 10
2 seasonings FALSE 15
3 whiskey TRUE 25
1 whiskey TRUE 40
1 pre_cooked TRUE 30
2 fresh_pie FALSE 10
3 fresh_salad FALSE 5
Any help or advice with this is greatly appreciated.
CodePudding user response:
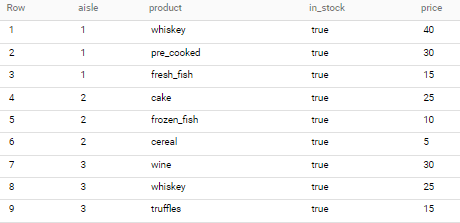
Use below
select *
from your_table
where in_stock
qualify 3 >= row_number() over(partition by aisle order by price desc)
if applied to sample data in your question - output is
CodePudding user response:
Use HAVING if you want to reference aliases
SELECT * FROM
(SELECT ROW_NUMBER() OVER (PARTITION BY aisle ORDER BY price DESC) AS high_prices, aisle,
price, product
FROM `a_database.shopping.grocery_stores`
WHERE in_stock = TRUE
GROUP BY aisle ) t1
WHERE high_prices <= 3
ORDER BY price;
CodePudding user response:
Use subquery:
select *
from (select row_number() over (partition by aisle order by price desc) row_number,
aisle,
price,
product
from a_database.shopping.grocery_stores
where in_stock is true) a
where row_number <= 3