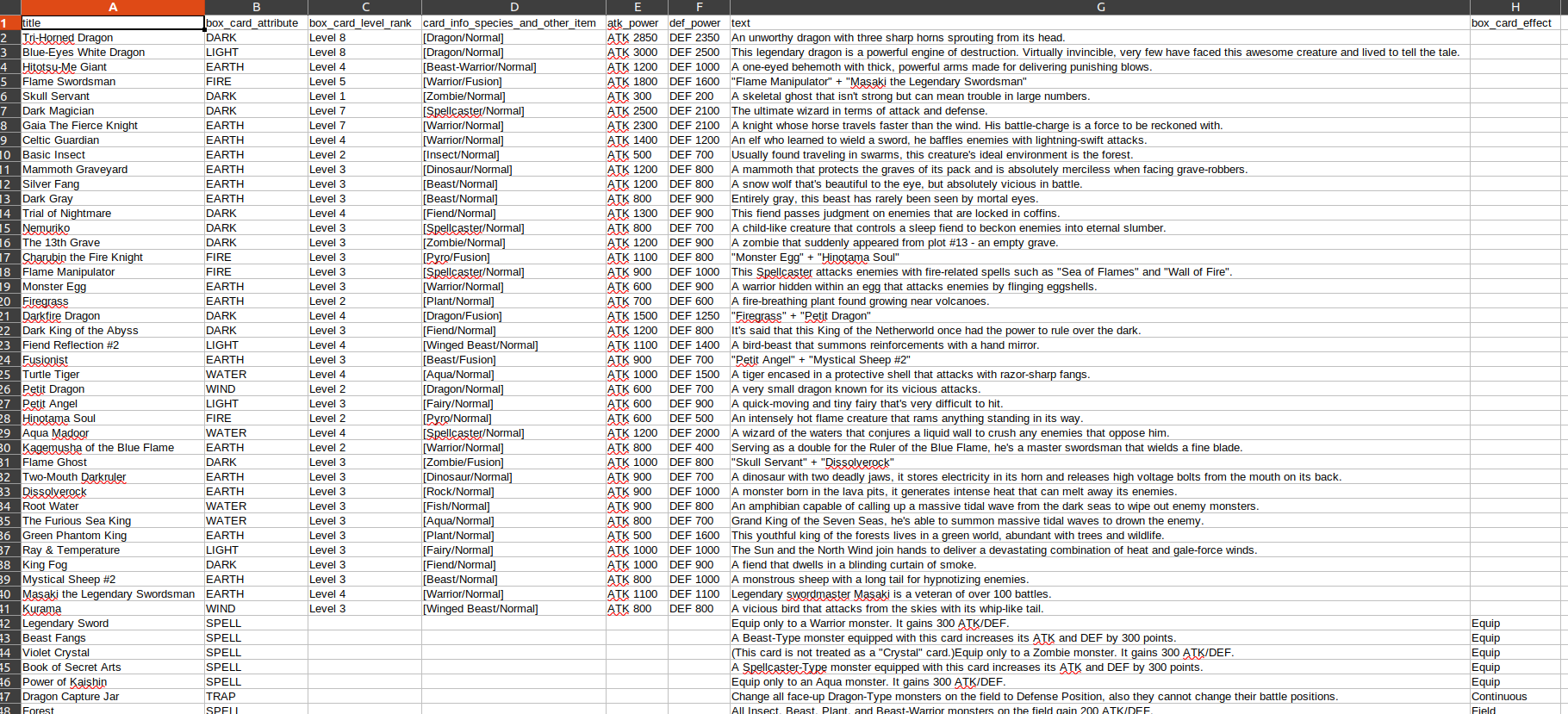
I'm using Python and BS4 and I'm able to grab the top entry from the page, but I'm looking to get all of them.
cardAttr = soup.find(class_='box_card_attribute').find("span", {"class": False}).text
cardAttr = soup.select_one('span.box_card_attribute >span').text
Both of the above will give me the first iteration, but trying to use find_all gives me an AttributeError. Below is a snippet of the HTML.
<div id="card_list" >
<div >
<div >
<img id="card_image_0_1" alt="Tri-Horned Dragon" title="Tri-Horned Dragon" >
</div>
<dl >
<dd >
<span ></span>
<span >Tri-Horned Dragon</span>
</dd>
<dd >
<div style="background-color:#e86d6d;color:#e86d6d">
<p>SE</p>
<span style="background-color:#fff4f4;border-color:#e86d6d;color:#e86d6d; ">
Secret Rare
</span>
</div>
</dd>
<dd >
<a href="javascript:void(0);" title="Remove this card from the list.">
<span>X</span>
<input type="hidden" value="">
<input type="hidden" value="4711">
</a>
</dd>
<dd >
<span >
<img src="external/image/parts/attribute/attribute_icon_dark.png" alt="DARK" title="DARK">
<span>DARK</span>
</span>
Currently I can grab the 'DARK' text, but I can't seem to get it to run through the entirety of the page as I could with class=card_name.
If needed this is the url I'm looking at.