I've been going off of data transpose applications but I wasn't able to tweak it as I expected in order to get the following output.
Here is the input data:
df = [
'| Series Name | Series ID | View Description | Year | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |',
'| Food | CUUR0000SAF1 | 12-Month Percent Change | 2010 | 0.03 | 0.018 | 0.014 | -0.002 | 0.044 | 0.14 | 0.024 | 0.088 | 0.012 | 0.25 | 0.045 | 0.041 |',
'| Food | CUUR0000SAF1 | 12-Month Percent Change | 2011 | 0.019 | -0.003 | 0.017 | 0.036 | 0.002 | 0.041 | 0.046 | 0.02 | 0.022 | 0.09 | 0.012 | 0.022 |',
'| Food | CUUR0000SAF1 | 12-Month Percent Change | 2012 | -0.034 | 0.041 | -0.002 | 0.019 | 0.046 | 0.047 | 0.018 | -0.62 | -0.052 | -0.074 | 0.037 | 0.029 |',
'| Food | CUUR0000SAF1 | 12-Month Percent Change | 2013 | 0.03 | 0.053 | 0.002 | 0.014 | -0.004 | 0.088 | 0.024 | 0.082 | 0.042 | -0.05 | -0.014 | 0.039 |',
]
And this is how it looks:
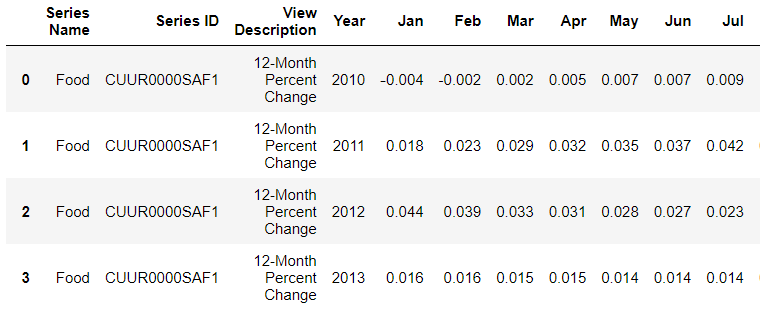
Expected output: (This is the optimal solution as it would be in excel) Note that the input data that I included would reflect only the first row of the optimal solution.

Any clue or suggestion would be greatly appreciated. Thanks!
CodePudding user response:
Here's an approach that first melts the table into long form in order to create the "Month-Year" column, and then pivots on that column.
After pivoting however, the columns are in alphabetical instead of date-order which you can fix with a custom sorting function after the pivot.
Thank you for the example data. As a side-note in the future it would help to have your data easier to load into pandas. Try df.head().to_dict(orient='list') which produces a dict that is easily converted to a pd.DataFrame
import pandas as pd
df = pd.DataFrame({
'Series Name': ['Food', 'Food', 'Food', 'Food'],
'Series ID': ['CUUR0000SAF1', 'CUUR0000SAF1', 'CUUR0000SAF1', 'CUUR0000SAF1'],
'View Description': ['12-Month Percent Change',
'12-Month Percent Change',
'12-Month Percent Change',
'12-Month Percent Change'],
'Year': [2010, 2011, 2012, 2013],
'Jan': [0.03, 0.019, -0.034, 0.03],
'Feb': [0.018, -0.003, 0.041, 0.053],
'Mar': [0.014, 0.017, -0.002, 0.002],
'Apr': [-0.002, 0.036, 0.019, 0.014],
'May': [0.044, 0.002, 0.046, -0.004],
'Jun': [0.14, 0.041, 0.047, 0.088],
'Jul': [0.024, 0.046, 0.018, 0.024],
'Aug': [0.088, 0.02, -0.62, 0.082],
'Sep': [0.012, 0.022, -0.052, 0.042],
'Oct': [0.25, 0.09, -0.074, -0.05],
'Nov': [0.045, 0.012, 0.037, -0.014],
'Dec': [0.041, 0.022, 0.029, 0.039],
})
#Convert to long-form to create a new column called "Month Year" (might not be necessary?)
long_df = df.melt(
id_vars = ['Series Name','Series ID','View Description','Year'],
var_name = 'Month',
)
long_df['Month Year'] = long_df['Month'] '-' long_df['Year'].astype(str).str[2:]
#Pivot to the form you need
wide_df = long_df.pivot(
index = ['Series Name','Series ID','View Description'],
columns = 'Month Year',
values = 'value',
)
#Sort the columns (could probably be done directly with datetime?)
def custom_sorting(month_year):
month_order = [
'Jan', 'Feb', 'Mar', 'Apr',
'May', 'Jun', 'Jul', 'Aug',
'Sep', 'Oct', 'Nov', 'Dec',
]
month,year = month_year.split('-')
year = int(year)
return 10*year month_order.index(month)
col_order = sorted(wide_df.columns, key = custom_sorting)
final_df = wide_df[col_order].reset_index()
final_df.columns.name = None
print(final_df)
Output
