I am using Spark Scala on Databricks. I have a dataframe with a column, and all values in that column are strings. I want to create another column in which I will have the number of uppercase letters in the original column. An example would be like this:
val df = Seq(("Java",1), ("2000",0), ("python",0), ("ScAlA",3), ("AuguST/Car",4)).toDF("list", "qty_uppercase")
Which gives:
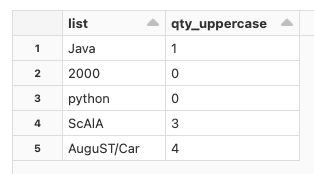
I don't know how to do this.
I have tried splitting the strings in the column "list" using the following command:
.withColumn("list_split", split($"list",""))
The result is below. But then I can't find the right way to iterate through each character of the new column.

For example, I have tried what is mentioned in this other question, and create a column using exists, but it doesn't work:
>>> .withColumn("count", $"list".exists(_.isUpper))
>>> error: value exists is not a member of org.apache.spark.sql.ColumnName
.withColumn("qty", $"list".exists(_.isUpper))
CodePudding user response:
One way is to split only by upper-case letters and count splits:
val df = Seq(("Java",1), ("2000",0), ("python",0), ("ScAlA",3), ("AuguST/Car",4)).toDF("list", "qty_uppercase")
df.withColumn("count", size(split($"list", "[A-Z]")) - 1).show()
which matches the expected counts:
---------- ------------- -----
| list|qty_uppercase|count|
---------- ------------- -----
| Java| 1| 1|
| 2000| 0| 0|
| python| 0| 0|
| ScAlA| 3| 3|
|AuguST/Car| 4| 4|
---------- ------------- -----