I have used kmeans to cluster my data. Now I want to cluster the clusters so that the clustered clusters consist of the individual clusters from the first round of clustering.
Minimal reproducible example:
# create dataframe
n1 = 336
n2 = 200
x_list = np.array(range(0, n1))
y_list = np.array(range(0, n2))
x_list = np.repeat([x_list], n2, axis=0).flatten() # width
y_list = np.repeat(y_list, n1, axis=0).flatten() # height
# normalize x, y to avoid skewing the clustering
norm_x = np.linalg.norm(x_list)
norm_y = np.linalg.norm(y_list)
normal_array_x = np.round(x_list / norm_x, 6)
normal_array_y = np.round(y_list / norm_y, 6)
data = {'x_position_norm': normal_array_x,
'y_position_norm': normal_array_y}
features = pd.DataFrame(data).to_numpy()
kmeans = KMeans(init='k-means ', n_clusters=16800, n_init=3, max_iter=3, random_state=1)
kmeans.fit(features)
kmeans2 = KMeans(init='k-means ', n_clusters=4200, n_init=3, max_iter=3, random_state=1)
kmeans2.fit(kmeans.cluster_centers_)
At the moment, I am clustering the cluster centers. Is there a better/ more efficient way to cluster that guarantees clusters in the second round of clustering are consisting of clusters from the first round of clusters?
CodePudding user response:
What you are looking for is the scikit-learn k-means implementation which has the option center_init='k-means ' (see here). So I would first do the clustering kmeans = KMeans(init='k-means ', n_clusters=16800, n_init=3, max_iter=3, random_state=1) kmeans.fit(features)
which will return the cluster centers. Then I would then use kmeans2 to compute the clusters on those cluster centers: kmeans2 = KMeans(init='k-means ', n_clusters=4200, n_init=3, max_iter=3, random_state=1) kmeans2.fit(kmeans.cluster_centers_)
which should then return the clusters.
CodePudding user response:
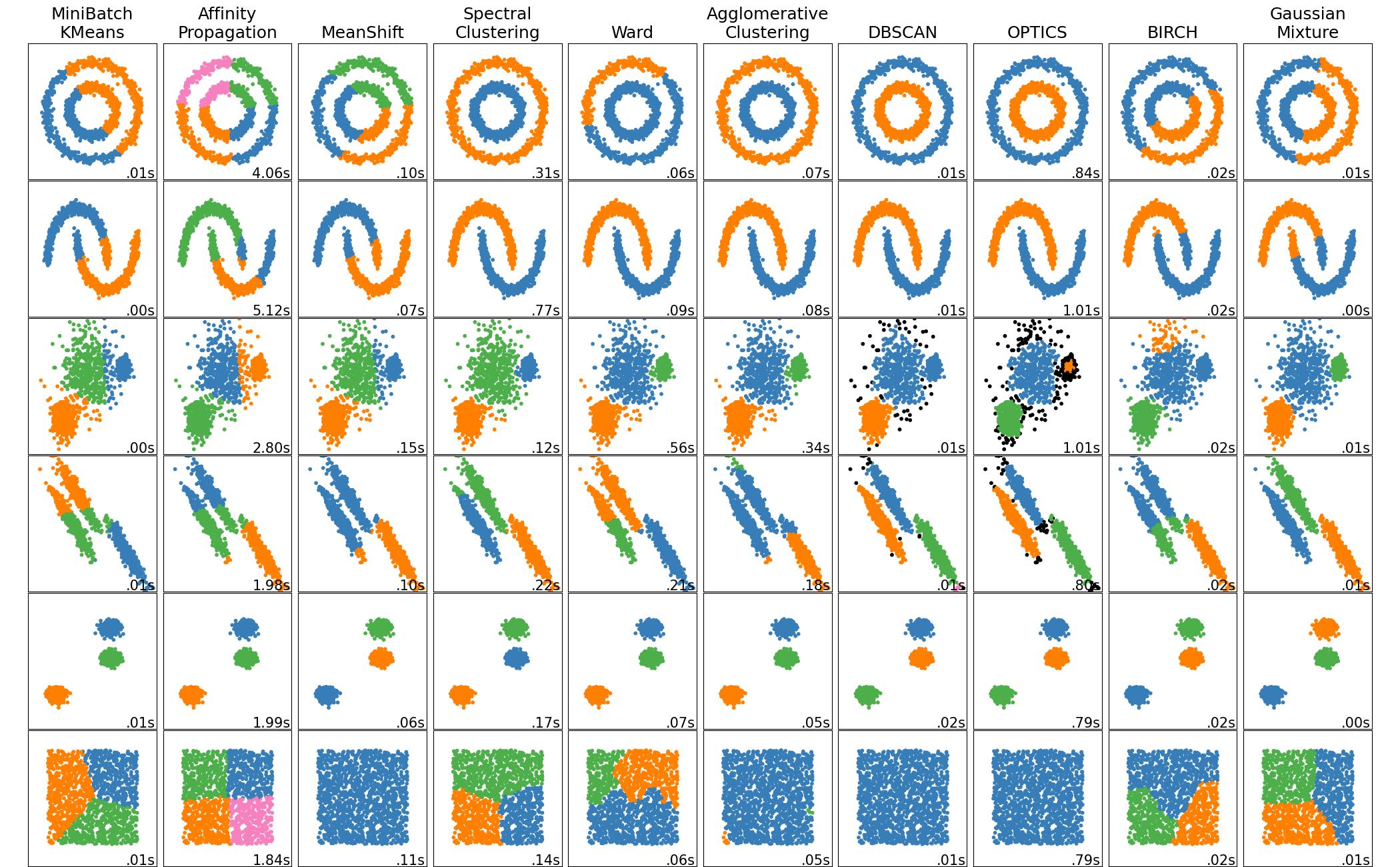
Each clustering method has its own characteristics. It only depends on what your data looks like.
For Bottom-up clustering, spectral clustering will work well.
Here is a list of clustering methods.