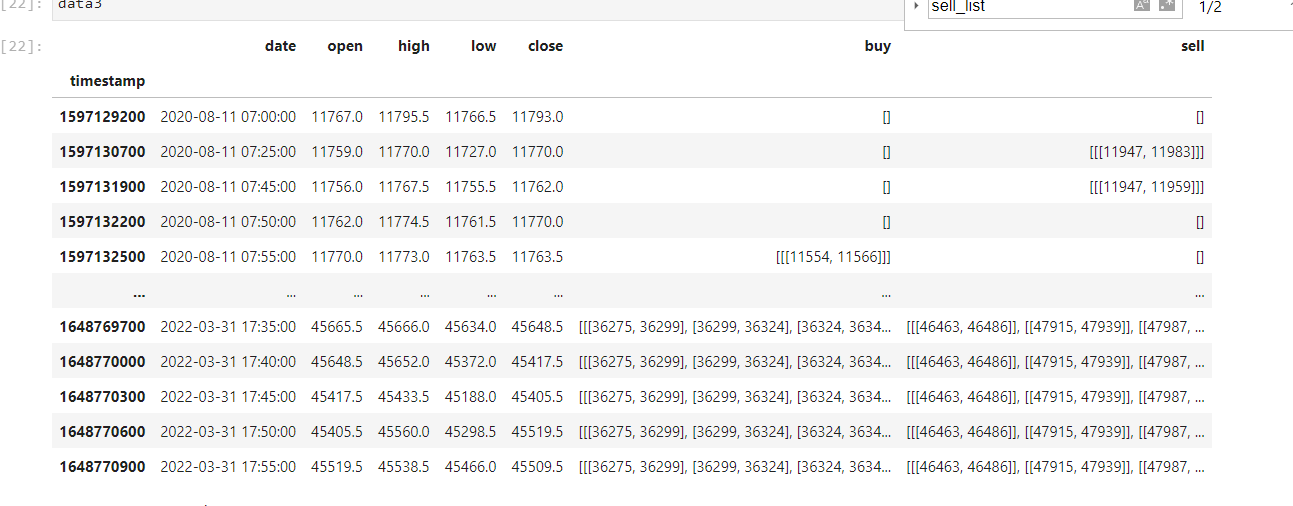
i am working whit a data of about 200,000 rows, in one column of the pandas i have some values that have a empty list, the most of them are list whit several values, here is a picture:
what i want to do is change the empty sets whit this set
[[close*0.95,close*0.94]]
where the close is the close value on the table, the for loop that i use is this one:
for i in range(1,len(data3.index)):
close = data3.close[data3.index==data3.index[i]].values[0]
sell_list = data3.sell[data3.index==data3.index[i]].values[0]
buy_list = data3.buy[data3.index==data3.index[i]].values[0]
if len(sell_list)== 0:
data3.loc[data3.index[i],"sell"].append([[close*1.05,close*1.06]])
if len(buy_list)== 0:
data3.loc[data3.index[i],"buy"].append([[close*0.95,close*0.94]])
i tried to make it work whit multithread but as i need to read all the table to do the next step i cant split the data, i hope you can help me to make a kind of lamda function to apply the df, or something, i am not to much skilled on this, thanks for reading!
the expected output of the row and column "buy" of and empty set should be [[[11554, 11566]]]
CodePudding user response:
Example data:
import pandas as pd
df = pd.DataFrame({'close': [11763, 21763, 31763], 'buy':[[], [[21763, 21767]], []]})
close buy
0 11763 []
1 21763 [[[21763, 21767]]]
2 31763 []
You could do it like this:
# Create mask (a bit faster than df['buy'].apply(len) == 0).
# Assumes there are no NaNs in the column. If you have NaNs, use pd.apply.
m = [len(l) == 0 for l in df['buy'].tolist()]
# Create triple nested lists and assign.
df.loc[m, 'buy'] = list(df.loc[m, ['close', 'close']].mul([0.95, 0.94]).to_numpy()[:, None][:, None])
print(df)
Result:
close buy
0 11763 [[[11174.85, 11057.22]]]
1 21763 [[[21763, 21767]]]
2 31763 [[[30174.85, 29857.219999999998]]]
Some explanation:
mis a boolean mask that selects the rows of the DataFrame with an empty list in the'buy'column:
m = [len(l) == 0 for l in df['buy'].tolist()]
# Or (a bit slower)
# "Apply the len() function to all lists in the column.
m = df['buy'].apply(len) == 0
print(m)
0 True
1 False
2 True
Name: buy, dtype: bool
We can use this mask to select where to calculate the values.
df.loc[m, ['close', 'close']].mul([0.95, 0.94])duplicates the'close'column and calculates the vectorised product of all the(close, close)pairs with(0.95, 0.94)to obtain(close*0.94, close*0.94)in each row of the resulting array.[:, None][:, None]is just a trick to create two additional axes on the resulting array. This is required since you want triple nested lists ([[[]]]).