1. The Data:
I have the following structure in a pandas DataFrame:
import pandas as pd
df = pd.DataFrame([['A', 'NaN', 'A', 'NaN'],['B', 'A', 'B/A', 'A'], ['B1', 'B', 'B1/B/A', 'B/A'],
['B2', 'B', 'B2/B/A', 'B/A'], ['C', 'B1', 'C/B1/B/A', 'B1/B/A'], ['D', 'B1', 'D/B1/B/A', 'B1/B/A'],
['E', 'B2', 'E/B2/B/A', 'B2/B/A']],
columns=['unit_id', 'group_id', 'new_unit_id', 'new_group_id'])
2. The issue and the goal:
I would like to replace the current unit_id and group_id with a value that appends it's parent structure as basically:
<unit_id> = <unit_id> '/' parent<unit_id>
and
<group_id> = parent<unit_id>
as you would see in a file tree structure or similar.
Something like this:
| index | unit_id | group_id | new_unit_id | new_group_id |
|---|---|---|---|---|
| 0 | A | NaN | A | NaN |
| 1 | B | A | B/A | A |
| 2 | B1 | B | B1/B/A | B/A |
| 3 | B2 | B | B2/B/A | B/A |
| 4 | C | B1 | C/B1/B/A | B1/B/A |
| 5 | D | B1 | D/B1/B/A | B1/B/A |
| 6 | E | B2 | E/B2/B/A | B2/B/A |
3. Attempts and approach:
I have tried mapping in place without creating 'new' columns, but run into issues where when the unit_id of a parent changes, it is not reflected in the group_id of its children.
df['unit_id'] = df['unit_id'] '/' df['group_id']
So it seems like I need to iterate row by row so the change on the previous row is factored in. Something like:
df['unit_id'] = df.apply(lambda row : row['unit_id'].replace(str(row['unit_id']), str(row['unit_id'] '/' row['group_id'])), axis=1)
This results in the same (inaccurate) values as above, but I think df.apply with the correct anonymous (lambda) function is a lot closer to what I need. Having trouble getting the syntax correct.
CodePudding user response:
This can be approach using graph theory.
This is your graph:
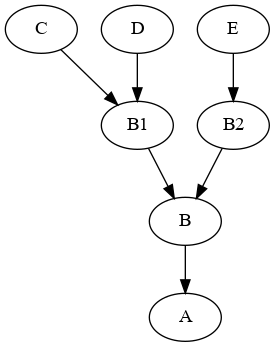
You can use networkx to compute your graph and find the shortest_path:
import networkx as nx
# ensure real NaN
df = df.replace('NaN', np.nan)
G = nx.from_pandas_edgelist(df.dropna(subset='group_id'),
source='unit_id', target='group_id',
create_using=nx.DiGraph)
#get final item
last = list(nx.topological_sort(G))[-1]
# get simple paths
df['new_unit_id'] = ['/'.join(nx.shortest_path(G, s, last))
if not pd.isna(s) else float('nan')
for s in df['unit_id']]
df['new_group_id'] = df['new_unit_id'].str.extract(r'[^/] /(. )')
output:
unit_id group_id new_unit_id new_group_id
0 A NaN A NaN
1 B A B/A A
2 B1 B B1/B/A B/A
3 B2 B B2/B/A B/A
4 C B1 C/B1/B/A B1/B/A
5 D B1 D/B1/B/A B1/B/A
6 E B2 E/B2/B/A B2/B/A