My df has a price column that looks like
0 2125.000000
1 14469.483703
2 14101.832820
3 20287.619019
4 14469.483703
...
12561 2490.000000
12562 2931.283333
12563 1779.661017
12566 2200.000000
12567 2966.666667
I want to remove all the rows of df with outliers in price_m2 column. I tried two methods :
1st:
df_w_o = df[np.abs(df.price_m2-df.price_m2.mean())<=(1*df.price_m2.std())]
2nd :
df['z_score'] = (df['price_m2'] - df['price_m2'].mean()) / df['price_m2'].std()
df_w_o = df[(df['z_score'] < 1) & (df['z_score'] > -1)]
When I check my min max after I get :
print(df_w_o.price_m2.min())
print(df_w_o.price_m2.max())
0.0
25438.022812290565
Before the removal I get :
print(df.price_m2.min())
print(df.price_m2.max())
0.0
589933.4267822268
This doesn't feel right, how can I get this large of a price range on data that are supposed to be about real estate. In this example 0 is the extreme low and remains after the outliers removal.
CodePudding user response:
I suggest you to use neulab library (See: 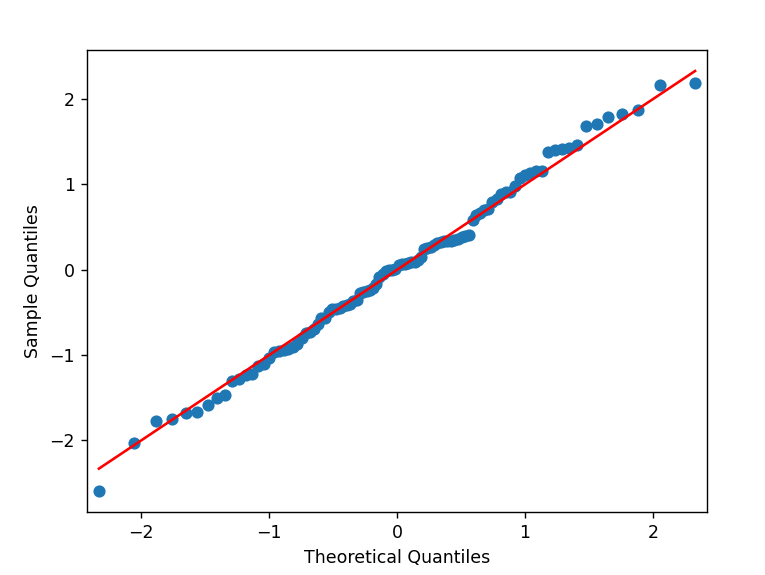
However, we can completely skew this with one single outlier.
outlier = 600000
df.loc[n] = outlier
qqplt = sm.qqplot(df["price"], line = 's',fit = True)
plt.show()
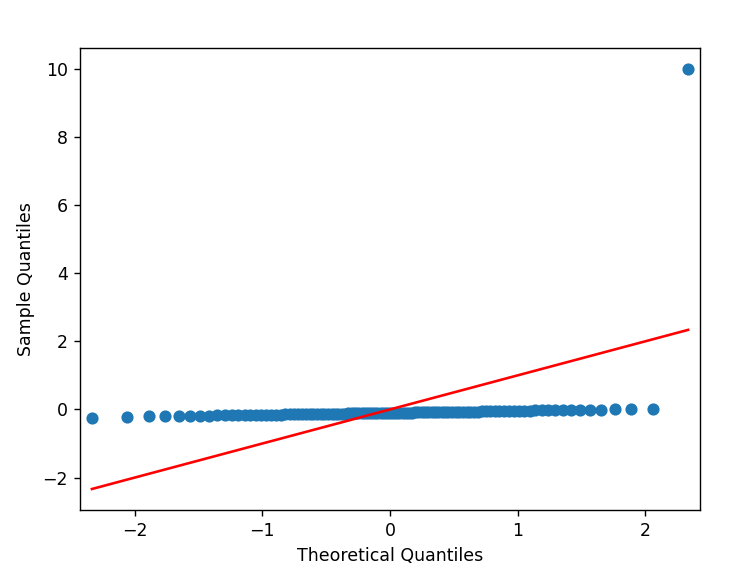
Anytime we talk about outlier removal and it "doesn't feel right", we really need to take a step back to look at the data. As @kndahl suggest, using a package that includes heuristics and methods for data removal is good. Otherwise, gut feelings should be backed up with your own statistical analysis.
Finally, as to why 0 was still in the final dataset, let's take another look. We will add 0 to the dataset and run your outlier removal. First, we'll look at running your default outlier removal then we will first remove the extremely high $600,000 before running your outlier method.
## simulated data with 0 also added
df.loc[n 1] = 0
df_w_o = df[np.abs(df.price-df.price.mean())<=(1*df.price.std())]
print(f"With the high outlier of 600,000 still in the original dataset, the new range is \nMin:{df_w_o.price.min()}\nMax:{df_w_o.price.max()}")
## With the high outlier of 600,000 still in the original dataset, the new range is
## Min:0.0
## Max:31809.263871962823
## now lets remove the high outlier first before doing our outlier removal
df = df.drop(n)
df_w_o = df[np.abs(df.price-df.price.mean())<=(1*df.price.std())]
print(f"\n\nWith the outlier of 600,000 removed prior to analyzing the data, the new range is \nMin:{df_w_o.price.min()}\nMax:{df_w_o.price.max()}")
## With the outlier of 600,000 removed prior to analyzing the data, the new range is
## Min:21241.61391985022
## Max:28690.87204218316
In this simulated case, the high outlier skewed the statistics so much that 0 was in the range of one standard deviation. Once we scrubbed the data before processing, that 0 was removed. Related, this may be better on Cross Validated with a more complete dataset provided.
CodePudding user response:
@SlimPun, this is what I meant:
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.normal(loc=10,scale=5,size=1000)) ## 1000 itens in price column
df.columns=["Price"]
Replace outliers by nan:
df[(df.Price>(np.mean(df.Price) 2*np.std(df.Price))) | (df.Price<(np.mean(df.Price)-2*np.std(df.Price)))]=np.nan
Drop outliers
df=df.dropna(how='all')
df.shape ## (951,1) - without outliers ** this can change according to your distribution given by numpy