I want to merge 2 dataframes without using the function '.merge' and I try to assign a value to a dataframe column based on an interval and an id.
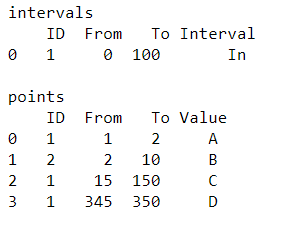
intervals = pd.DataFrame(
columns=["ID", "From", "To", "Interval"], data=[[1, 0, 100, "In"]]
)
print("intervals\n", intervals, "\n")
points = pd.DataFrame(
columns=["ID", "From", "To", "Value"],
data=[[1, 1, 2, "A"], [2, 2, 10, "B"], [1, 15, 150, "C"], [1, 345, 350, "D"]],
)
print('points\n',points,'\n')
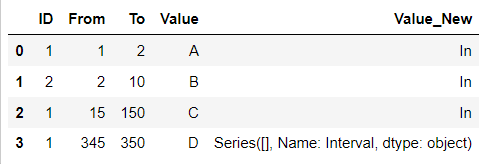
My attempt:
def calculate_value(x):
return intervals.loc[
(x >= intervals["From"]) & (x < intervals["To"]), "Interval"
].squeeze()
desired_result = points.copy()
desired_result['Value_New'] = desired_result['From'].apply(calculate_value)
and the output:
But I want this:
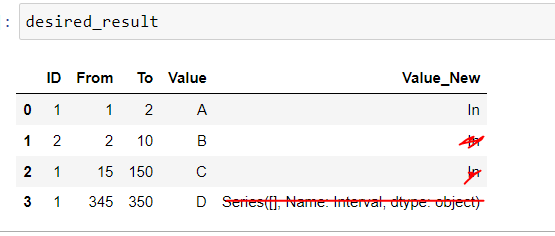
The points must be between the interval, that's why "15 - 150" doesn't have value in "Value_New".
How to do that?
Source: How to assign values based on an interval in Pandas
CodePudding user response:
Here is one way to do it:
# Filter "points" dataframe to retain only the rows that match given conditions
mask = (
(points["ID"].isin(intervals["ID"].values))
& (points["From"] >= intervals["From"].values[0])
& (points["To"] <= intervals["To"].values[0])
)
# Add a new column "Value_New" to "points" dataframe and fill it once with bool values
# and then with the desired values ("In" or empty string)
points = points.assign(Value_New=mask).pipe(
lambda df: df.assign(Value_New=df["Value_New"].apply(lambda x: "In" if x else ""))
)
print(points)
# Output
ID From To Value Value_New
0 1 1 2 A In
1 2 2 10 B
2 1 15 150 C
3 1 345 350 D