Here is a Postgres code I created, it works. Is there a way to code it in a more efficient way? My goal is to get how much periods a given date falls from 2014-03-01. One period is a half-year starting from March or September.
I updated this code below on 2022-05-18 at 10:19 UTC 2
select date,
dense_rank() over (order by half_year_mar_sep) as period_index
from
(
select date as date,
case when extract(month from date) = 12 then (extract(year from date) || '-09-01')
when extract(month from date) in (1, 2) then (extract(year from date) - 1 || '-09-01')
when extract(month from date) in (3, 4, 5) then (extract(year from date) || '-03-01')
when extract(month from date) in (6, 7, 8) then (extract(year from date) || '-03-01')
else extract(year from date) || '-09-01'
end::date as half_year_mar_sep
from
(
select generate_series(date '2014-03-01', CURRENT_DATE, interval '1 day')::date as date
) s1
) s2
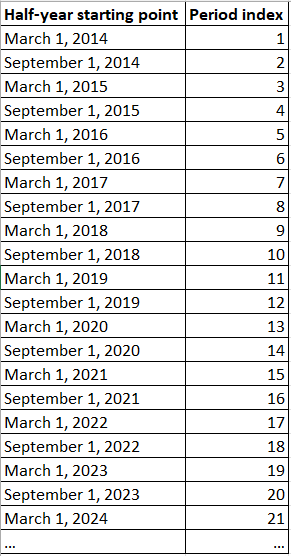
If I encapsulate the code above into select min(date), period_index from (<code above>) s3 group by 2 order by 1 then here is the result what I need:
CodePudding user response:
WITH cte AS (
SELECT
date1::date,
rank() OVER (ORDER BY date1)
FROM generate_series(date '2014-03-01', CURRENT_DATE interval '1' month, interval '6 month') g (date1)
),
cteall AS (
SELECT
all_date::date
FROM
generate_series(date '2014-03-01', CURRENT_DATE interval '1' month, interval ' 1 day') s (all_date)
),
cte3 AS (
SELECT
*
FROM
cteall c1
LEFT JOIN cte c2 ON date1 = all_date
),
cte4 AS (
SELECT
*,
count(rank) OVER w AS ct_str
FROM
cte3
WINDOW w AS (ORDER BY all_date))
SELECT
*,
rank() OVER (PARTITION BY ct_str ORDER BY all_date) AS rank1,
dense_rank() OVER (ORDER BY all_date) AS dense_rank1
FROM
cte4;
Hope it's not intimidating. personally I found cte is a good tool, since it make logic more clearly.
demo
useful link: How to do forward fill as a PL/PGSQL function
If some column don't need, you can simple replace * with the columns you want.
CodePudding user response:
Based on @Mark's answer I wrote this code below, but it's not simpler than the original code.
select s.date,
m.period_index
from
(
select date::date as half_year_start,
rank() over (order by date) as period_index,
coalesce(lead(date::date, 1) over (), CURRENT_DATE) as following_half_year_start
from generate_series(date '2014-03-01', CURRENT_DATE interval '1' month, interval '6 month') as date
) m
left join
(
select generate_series(date '2014-03-01', CURRENT_DATE, interval '1 day')::date as date
) s
on s.date between m.half_year_start and m.following_half_year_start
;