I have a time-dependent data set, where I (as an example) am trying to do some hyperparameter tuning on a Lasso regression.
For that I use sklearn's TimeSeriesSplit instead of regular Kfold CV, i.e. something like this:
tscv = TimeSeriesSplit(n_splits=5)
model = GridSearchCV(
estimator=pipeline,
param_distributions= {"estimator__alpha": np.linspace(0.05, 1, 50)},
scoring="neg_mean_absolute_percentage_error",
n_jobs=-1,
cv=tscv,
return_train_score=True,
max_iters=10,
early_stopping=True,
)
model.fit(X_train, y_train)
With this I get a model, which I can then use for predictions etc. The idea behind that cross validation is based on this:
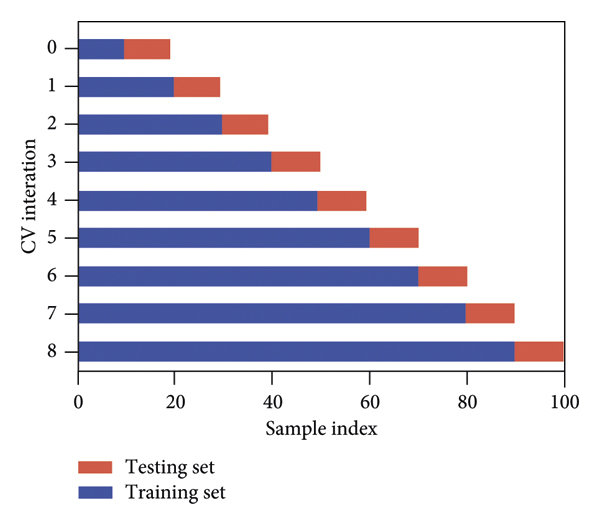
However, my issue is that I would actually like to have the predictions from all the test sets from all cv's. And I have no idea how to get that out of the model ?
If I try the cv_results_ I get the score (from the scoring parameter) for each split and each hyperparameter. But I don't seem to be able to find the prediction values for each value in each test split. And I actually need that for some backtesting. I don't think it would be "fair" to use the final model to predict the previous values. I would imagine there would be some kind of overfitting in that case.
So yeah, is there any way for me to extract the predicted values for each split ?
CodePudding user response:
You can have custom scoring functions in GridSearchCV.With that you can predict outputs with the estimator given to the GridSearchCV in that particular fold.
from the documentation scoring parameter is
Strategy to evaluate the performance of the cross-validated model on the test set.
from sklearn.metrics import mean_absolute_percentage_error
def custom_scorer(clf, X, y):
y_pred = clf.predict(X)
# save y_pred somewhere
return -mean_absolute_percentage_error(y, y_pred)
model = GridSearchCV(estimator=pipeline,
scoring=custom_scorer)
The input X and y in the above code came from the test set. clf is the given pipeline to the estimator parameter.
Obviously your estimator should implement the predict method (should be a valid model in scikit-learn). You can add other scorings to the custom one to avoid non-sense scores from the custom function.