I have a dataframe like as below
stu_id,Mat_grade,sci_grade,eng_grade
1,A,C,A
1,A,C,A
1,B,C,A
1,C,C,A
2,D,B,B
2,D,C,B
2,D,D,C
2,D,A,C
tf = pd.read_clipboard(sep=',')
My objective is to
a) Find out how many different unique grades that a student got under Mat_grade, sci_grade and eng_grade
So, I tried the below
tf['mat_cnt'] = tf.groupby(['stu_id'])['Mat_grade'].nunique()
tf['sci_cnt'] = tf.groupby(['stu_id'])['sci_grade'].nunique()
tf['eng_cnt'] = tf.groupby(['stu_id'])['eng_grade'].nunique()
But this doesn't provide the expected output. Since, I have more than 100K unique ids, any efficient and elegant solution is really helpful
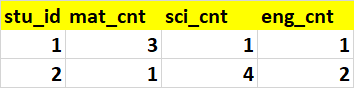
I expect my output to be like as below
CodePudding user response:
Use:
cols = ['Mat_grade','sci_grade', 'eng_grade']
new = ['mat_cnt','sci_cnt','eng_cnt']
d = dict(zip(cols, new))
df = tf.groupby(['stu_id'], as_index=False)[cols].nunique().rename(columns=d)
print (df)
stu_id mat_cnt sci_cnt eng_cnt
0 1 3 1 1
1 2 1 4 2
Another idea:
cols = ['Mat_grade','sci_grade', 'eng_grade']
new = ['mat_cnt','sci_cnt','eng_cnt']
d = {v: (k,'nunique') for k, v in zip(cols, new)}
print (d)
{'mat_cnt': ('Mat_grade', 'nunique'),
'sci_cnt': ('sci_grade', 'nunique'),
'eng_cnt': ('eng_grade', 'nunique')}
df = tf.groupby(['stu_id'], as_index=False).agg(**d)
print (df)
stu_id mat_cnt sci_cnt eng_cnt
0 1 3 1 1
1 2 1 4 2