How to calculate the difference between max and min date for each user
I have tried going like -
df['diff'] = (df['purschase_date'].max() - df['purschase_date'].min()).dt.days
But it has calculated across all rows and for not this particular user, how do I go to calculating it by user_id
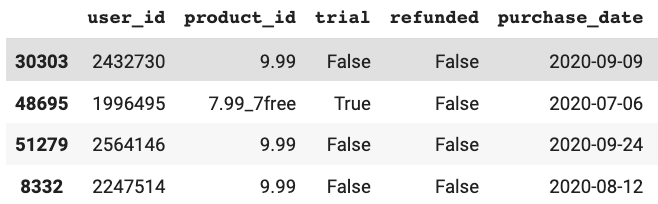
Here is how dataframe looks like
CodePudding user response:
try this :
import pandas as pd
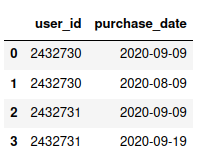
d = {'user_id': [2432730,2432730, 2432731,2432731],
'purchase_date': ["2020-09-09", "2020-08-09","2020-09-09","2020-09-19"]}
df = pd.DataFrame(data=d)
df['purchase_date']=pd.to_datetime(df['purchase_date'])
Input :
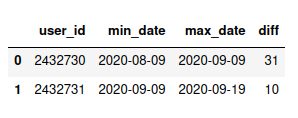
max_date=df[['user_id','purchase_date']].groupby(by='user_id').max().reset_index().rename(columns={'purchase_date':'max_date'})
min_date=df[['user_id','purchase_date']].groupby(by='user_id').min().reset_index().rename(columns={'purchase_date':'min_date'})
min_date=min_date.join(max_date['max_date'])
min_date['diff']=(min_date['max_date']-min_date['min_date']).dt.days
min_date
Output :
CodePudding user response:
You just need a groupby user_id to calculate the difference
df.groupby('user_id')['purchase_date'].max() - df.groupby('user_id')['purchase_date'].min()
This will create a series and it cannot be directly assigned to the df as there are only two users so you will have two rows. So you need to assign the results back to the dataframe
CodePudding user response:
create new dataframe grouped per id with named cols for min and max values of dates, later merge with original.
data input:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"user_id": (np.random.randint(10000,10004,15, dtype="int32")),
"purchase_date": (pd.date_range(start='2022-01-01', periods=15, freq='8H')),
"C": pd.Series(1, index=list(range(15)), dtype="float32"),
"D": np.array([5] * 15, dtype="int32"),
"E": "foo",
})
df['purchase_date'] = pd.to_datetime(df['purchase_date']).dt.normalize()
# Solution
df_grouped = df.groupby(['user_id']).agg(
date_min=('purchase_date', 'min'),
date_max=('purchase_date', 'max'))\
.reset_index()
df_grouped['diff']=(df_grouped['date_max']-df_grouped['date_min']).dt.days
df1 = pd.merge(df, df_grouped)
df1
Out:
user_id purchase_date C D E date_min date_max diff
0 10001 2022-01-01 1.0 5 foo 2022-01-01 2022-01-04 3
1 10001 2022-01-02 1.0 5 foo 2022-01-01 2022-01-04 3
2 10001 2022-01-03 1.0 5 foo 2022-01-01 2022-01-04 3
3 10001 2022-01-04 1.0 5 foo 2022-01-01 2022-01-04 3
4 10000 2022-01-01 1.0 5 foo 2022-01-01 2022-01-04 3
5 10000 2022-01-02 1.0 5 foo 2022-01-01 2022-01-04 3
6 10000 2022-01-03 1.0 5 foo 2022-01-01 2022-01-04 3
7 10000 2022-01-04 1.0 5 foo 2022-01-01 2022-01-04 3
8 10002 2022-01-01 1.0 5 foo 2022-01-01 2022-01-05 4
9 10002 2022-01-02 1.0 5 foo 2022-01-01 2022-01-05 4
10 10002 2022-01-03 1.0 5 foo 2022-01-01 2022-01-05 4
11 10002 2022-01-05 1.0 5 foo 2022-01-01 2022-01-05 4
12 10002 2022-01-05 1.0 5 foo 2022-01-01 2022-01-05 4
13 10003 2022-01-04 1.0 5 foo 2022-01-04 2022-01-05 1
14 10003 2022-01-05 1.0 5 foo 2022-01-04 2022-01-05 1