I have a pandas dataframe where I wanted to find the percentage cutoff for most prevalent brand customer added to his cart.(New column: Percentage Cutoff for brand)
| customerID | Date | Brand | Brand Count | Percentage Cutoff for brand |
|---|---|---|---|---|
| 1 | 1-1-2021 | Tomy Hilfigure | 3 | 75% |
| 1 | 1-1-2021 | Adidas | 1 | 75% |
| 2 | 2-1-2021 | Club Room | 2 | 66% |
| 2 | 2-1-2021 | Levis | 1 | 66% |
| 2 | 3-1-2021 | Adidas | 4 | 50% |
| 2 | 3-1-2021 | Polo | 4 | 50% |
For customer 1, the percentage cutoff will be 75% as he has added 3 items of Tomy Hilfigure brand in his cart and 1 item of Adidas brand(25%) hence the percentage cutoff for the customer 1 is 75% for date 1-1-2021.
For customer 2, on date 2-1-2021, the percentage cutoff will be 66.67% as he added 2 items of Club room brand(66.66%) and 1 item of Levis brand(33%).
I am using pandas group by function but couldn't able to find the " Percentage Cutoff for brand".It would be great if you could give me a direction. Thank you.
CodePudding user response:
Let me know if the cutoff calculation logic is not right, I used max_brand_count / total_brand_count
# Grouping by customerID and Date to calculate max and total brand count
gdf = df.groupby(['customerID', 'Date']) \
.agg(
max_brand_count=('Brand Count', 'max'),
total_brand_count=('Brand Count', 'sum')
) \
.reset_index()
# Calculate Percentage Cutoff for brand by dividing max and total brand counts
gdf['Percentage Cutoff for brand'] = gdf['max_brand_count'] / gdf['total_brand_count']
# Formatting it to percentage
gdf['Percentage Cutoff for brand'] = ['{:,.2%}'.format(val) for val in gdf['Percentage Cutoff for brand']]
Output of this groupby:
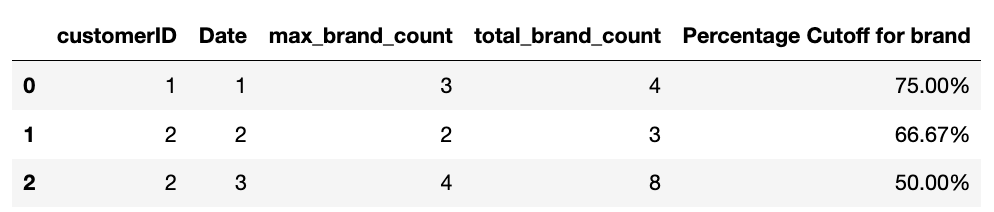
You can merge this to your original df if you want to have it all together.
final_df = df.merge(gdf, how='left', on=['customerID', 'Date'])