Can someone please assist me in reading the following data coming from csv using pandas? The labels in the first column may be more/less and the countries could also change. How do I iterate through each row and column to read and write these stats to sql provided that labels and countries get appended/removed? Thank you.
CSV 1
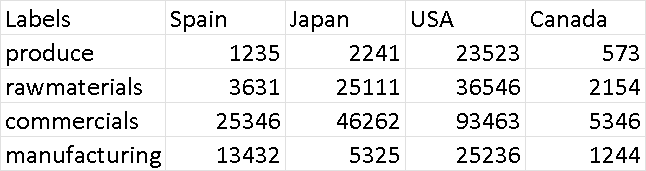
CSV 2

CodePudding user response:
You can actually use df.iterrows()
ex:
for index, rows in df.iterrows():
index # this will give you the index of the particular row
rows['column_name'] #this will give you the row of the particular column.
CodePudding user response:
You can read csv file using
import pandas as pd
# reading a csv file
df = pd.read_csv('filepath')
You can iterate through dataframe using
for index, row in df.iterrows():
# details of the country
print (row['countryone'], row['countrytwo'])
# get the country name
print (row['country_name'])
You can also check the country by iterating through the columns
for col_name in df.columns:
print(col_name)
Iteration through every data in the file can affect the performance of the program and the database. So if you are trying to save the data in the dataframe at once you can try this too
df.to_sql('short description', connection, if_exists='append', index=False)
connection is the database connection