I'm trying to multiply together some 4 dimensional arrays (block matrices) in the following way:
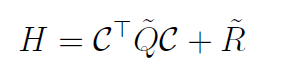
where C has shape (50,50,12,6), Q has shape (50,50,12,12), R has shape (50,50,6,6),
I wonder how I should choose the correct axes to carry out tensor products? I tried doing matrix product in the following way:
H = np.tensordot(C_block.T,Q_block) @ C_block
But a value error is returned:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_2976/3668270968.py in <module>
----> 1 H = np.tensordot(C_block.T,Q_block) @ C_block
ValueError: operands could not be broadcast together with remapped shapes [original->remapped]: (6,12,12,12)->(6,12,newaxis,newaxis) (50,50,12,6)->(50,50,newaxis,newaxis) and requested shape (12,6)
CodePudding user response:
Based on the sizes of your arrays, it looks like you are trying to do a regular matrix multiply on 50x50 arrays of matrices.
CT = np.swapaxes(C, 2, 3)
H = np.dot(np.dot(CT, Q), C) R
CodePudding user response:
Creating some arrays of the right shape mix - with 10 instead of 50 for the batch dimensions. That is, treating the first 2 dimensions as batch that is repeated across all arrays including the result.
The sum-of-products dimension is size 12, right and left for Q.
This is most easily expressed with einsum.
In [71]: N=10; C=np.ones((N,N,12,6)); Q=np.ones((N,N,12,12)); R=np.ones((N,N,6,6))
In [73]: res = np.einsum('ijkl,ijkm,ijmn->ijln',C,Q,C) R
In [74]: res.shape
Out[74]: (10, 10, 6, 6)
dot does not handle 'batches' right, hence the memory error in the other answer. np.matmul does though.
In [75]: res1 = C.transpose(0,1,3,2)@Q@C R
In [76]: res1.shape
Out[76]: (10, 10, 6, 6)
With all ones, the value test isn't very diagnostic, still:
In [77]: np.allclose(res,res1)
Out[77]: True
matmul/@ treats the first 2 dimensions as 'batch', and does a dot on the last 2. C.T in the equation should just swap the last 2 dimensions, not all.