I am learning X64 assembly language under Windows and MASM64 from the latest edition of the book "The art of 64 bit assembly language".
I have a question regarding that quote from the book:
You do have to worry about MMU page organization in memory in one situation. Sometimes it is convenient to access (read) data beyond the end of a data structure in memory. However, if that data structure is aligned with the end of an MMU page, accessing the next page in memory could be problematic. Some pages in memory are inaccessible; the MMU does not allow reading, writing, or execution to occur on that page. Attempting to do so will generate an x86-64 general protection (segmentation) fault and abort the normal execution of your program. If you have a data access that crosses a page boundary, and the next page in memory is inaccessible, this will crash your program. For example, consider a word access to a byte object at the very end of an MMU page, as shown in Figure 3-2.
As a general rule, you should never read data beyond the end of a data structure. If for some reason you need to do so, you should ensure that it is legal to access the next page in memory (alas, there is no instruction on modern x86-64 CPUs to allow this; the only way to be sure that access is legal is to make sure there is valid data after the data structure you are accessing).
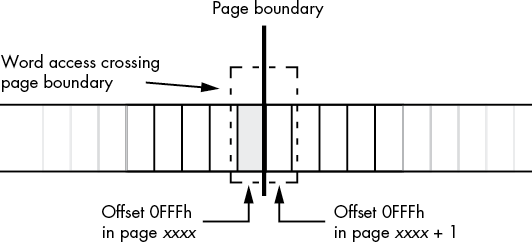
So my question is: let's say I have that exact case. A word variable at the very end of the data segment. How do I prevent the exception? By manually padding with 00h cells? Properly aligning every variable to its size? And if I do align everything, what will happen if the last variable is a qword that crosses the 4k boundary? How to prevent that?
Will MASM allocate another sequential data segment automatically to accomodate it?
CodePudding user response:
It's safe to read anywhere in a page that's known to contain any valid bytes, e.g. in static storage with an unaligned foo: dq 1. If you have that, it's always safe to mov rax, [foo].
Your assembler linker will make sure that all storage in .data, .rdata, and .bss is actually backed by valid pages the OS will let you touch.
The point your book is making is that you might have an array of 3-byte structs like RGB pixels, for example. x86 doesn't have a 3-byte load, so loading a whole pixel struct with mov eax, [rcx] would actually load 4 bytes, including 1 byte you don't care about.
Normally that's fine, unless [rcx 3] is in an unmapped page. (E.g. the last pixel of a buffer, ending at the end of a page, and the next page is unmapped). Crossing into another cache line you don't need data from is not great for performance, so it's a tradeoff vs. 2 or 3 separate loads like movzx eax, word ptr [rcx] / movzx edx, byte ptr [rcx 2]
This is more common with SIMD, where you can make more use of multiple elements at once in a register after loading them. Like movdqu xmm0, [rcx] to load 16 bytes, including 5 full pixels and 1 byte of another pixel we're not going to deal with in this vector.
(You don't have this problem with planar RGB where all the R components are contiguous. Or in general, AoS vs. SoA = Struct of Arrays being good for SIMD. You also don't have this problem if you unroll your loop by 3 or something, so 3x 16-byte vectors = 48 bytes covering 16x 3-byte pixels, maybe doing some shuffling if necessary or having 3 different vector constants if you need different constants to line up with different components of your struct or pixel or whatever.)
If looping over an array, you have the same problem on the final iteration. If the array is larger than 1 SIMD vector (XMM or YMM), instead of scalar for the last n % 4 elements, you can sometimes arrange to do a SIMD load that ends at the end of the array, so it partially overlaps with a previous full vector. (To reduce branching, leave 1..4 elements of cleanup instead of 0..3, so if n is a multiple of the vector width then the "cleanup" is another full vector.) This works great for something like making a lower-case copy of an ASCII string: it's fine to redo the work on any given byte, and you're not storing in-place so you don't even have store-forwarding stalls since you won't have a load overlapping a previous store. It's less easy for summing an array (where you need to avoid double-counting), or working in-place.
See also Is it safe to read past the end of a buffer within the same page on x86 and x64?
That's a challenge for strlen where you don't know whether the data you're allowed to read extends into the next page or not. (Unless you only read 1 byte at a time, which is 16x slower than you can go with SSE2.)
AVX-512 has masked load/store with fault suppression, so a vmovdqu8 xmm0{k1}{z}, [rcx] with k1=0x7F will effectively be a 15-byte load, not faulting even if the 16th byte (where the mask is zero) extends into an unmapped page. Same for AVX vmaskmovps and so on. But the store version of that is slow on AMD.
Attempting to do so will generate an x86-64 general protection (segmentation) fault
Actually a #PF page fault for an access that touches an unmapped or permission-denied page. But yes, same difference.