The text from a pdf I scraped is jumbled up in different elements. Not to mention, it deleted data when it was converted to a data frame. It's really hard to tell where the text should have been split since it seems like I got it correct in the below code. How do I split the text so that it looks looks like the original table?
mintz = "https://www.mintz.com/sites/default/files/media/documents/2019-02-08/State Legislation on Biosimilars.pdf"
mintzText = pdf_subset(mintz,pages = 2:23)
mintzText = pdf_text(mintzText)
q = data.frame(trimws(mintzText))
mintzdf <- q %>%
rename(x = trimws.mintzText.) %>%
mutate(x=strsplit(x, "\\n")) %>%
unnest(x)
View(mintzdf)
mintzDF=mintzdf[-c(1:2),]
mintzDF=mintzDF %>%
separate(x, c("a","State", "Substitution
Requirements","Pharmacy Notification Requirements
(to prescriber, patient, or others)","Recordkeeping
Requirements"))%>%
select(-a)
View(mintzdf)
what it looks like
what it should look like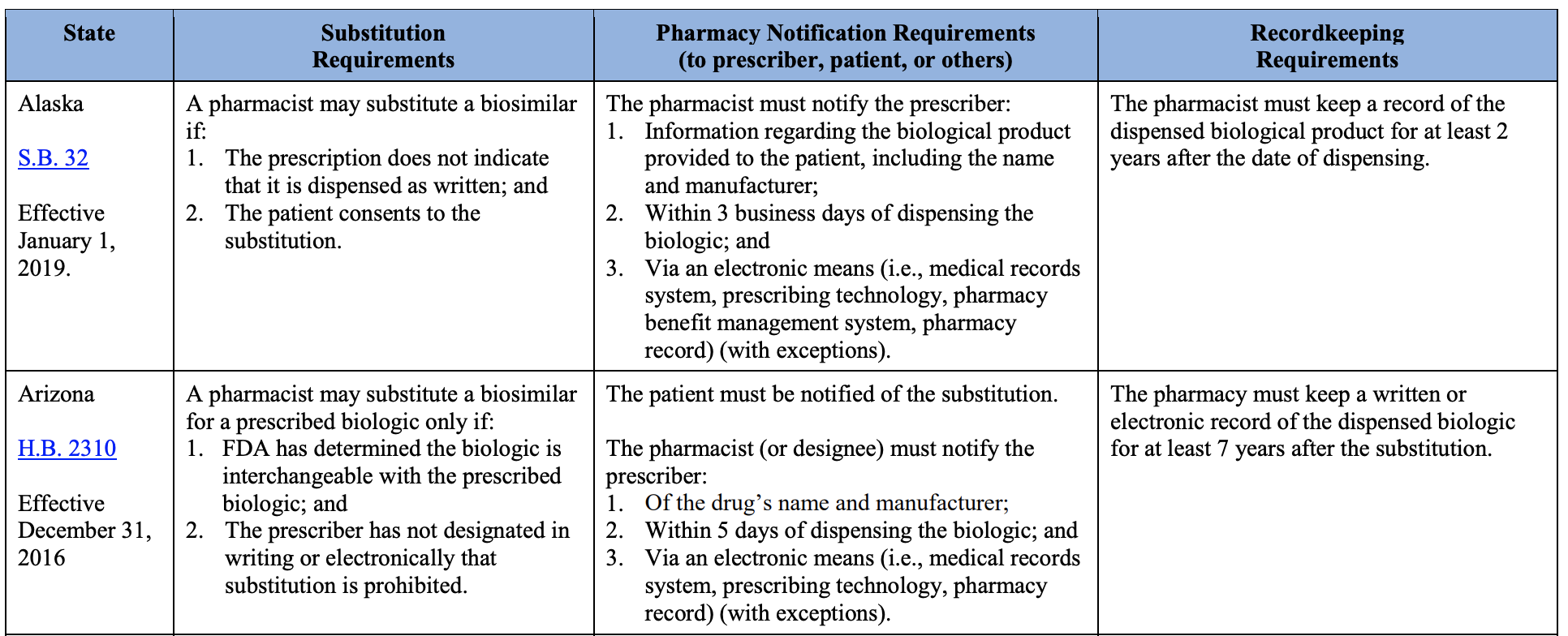
CodePudding user response:
Pdf stored order for a page may be random or bottom rows upwards as there are no key press order rules for when lasers charge a drum (The design requirement for PDF introduction)
We are lucky if the order can be sensibly extracted, but this is a very well ordered PDF. So remember there is no need to observe the grid simply output by rows with spaces that with luck form columns.
In this case using poppler pdftotext with no controls a single page text order could look like this with the first column headed State and the second starting with Substitution\nRequirements\n so clearly there may be head scratching why State is not spaced away from Alaska? but then it is PDF after all, so expect there are no rules.
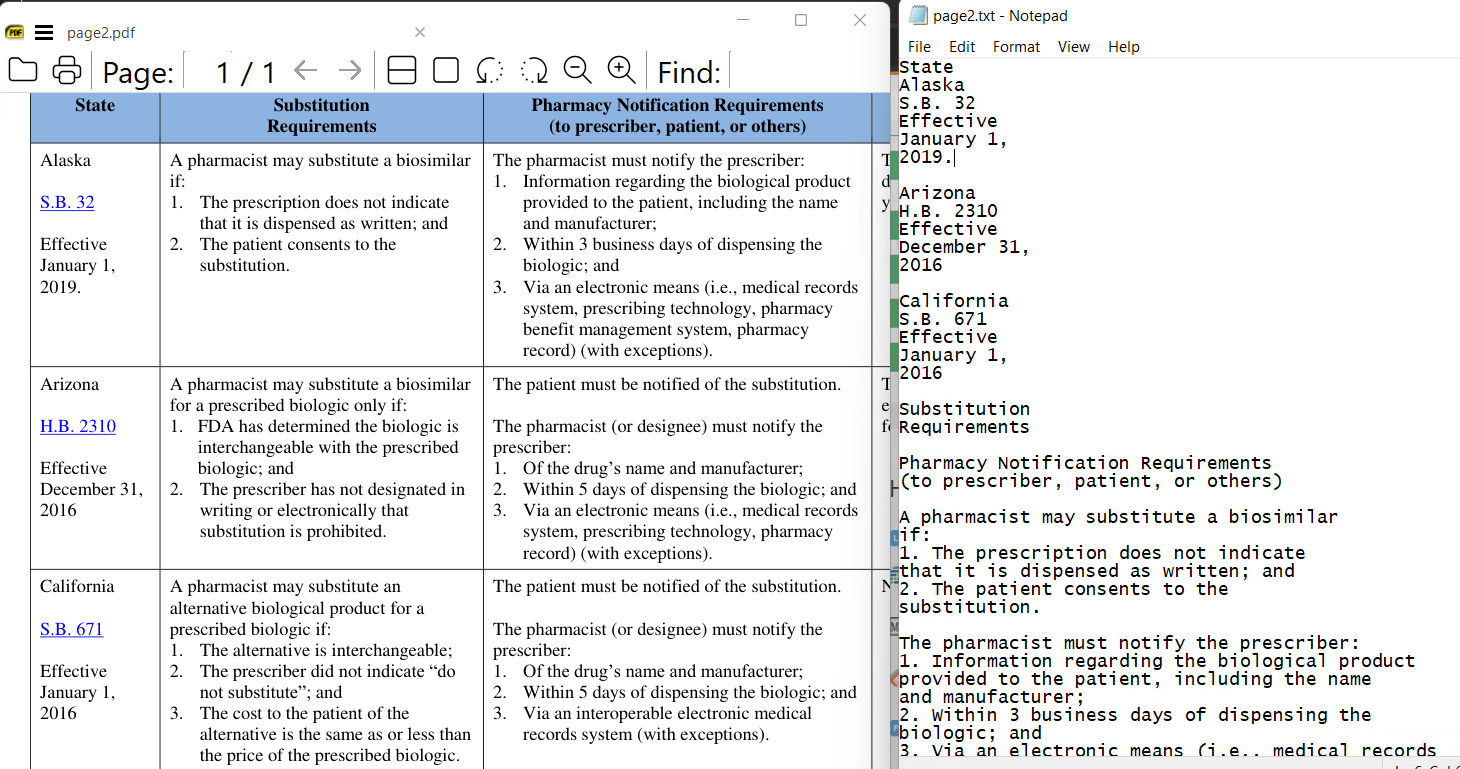
Looks like it was written down one column then across two then perhaps down the last ?.
Dependant on the very different page variations, I would attempt to target as vertical strips, rather than horizontals. so set a template as 4 vertical page high zones and then hope the horizontal breaks can be determined as matches. The alternative (probably better) is extract as a tabular layout and xpdf pdftotext may then give a better result.
Or use a python table extractor like pdfminer.