Hi I am trying this thing but it doesn't work.
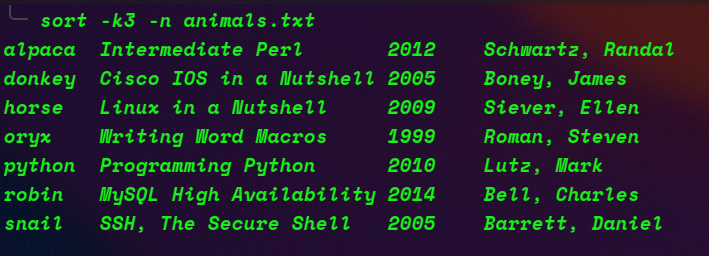
I know that it doesn't work because each line has different number of columns when words are separated by space but can we do the intended job any way.
CodePudding user response:
sort allows us to designate the field terminator as well as which fields (and optionally substrings of fields) to sort by.
If we set the field delimiter as a linefeed (\n) the entire line becomes a single field.
From here we can designate a substring of field #1 to sort by; -k1.x,1.y says to sort by field #1 from position x to position y (with the first column/character of the field/line being 1).
Sample input:
$ cat animals.txt
1 2 3 4 5 6
123456789012345678901234567890123456789012345678901234567890
alpaca Intermediate Perl 2012 Schwatz, Randal
donkey Cisco IOS in a Nutshell 2005 Boney, James
horse Linux in a Nutshell 2009 Siever, Ellen
Where:
- the first 2 lines (the scale) do not exist in the file; the scale shows us ...
- the
yearpart of the line runs from position36to39
Pulling all of this into a sort call:
# sort numerically by year (ascending)
$ sort -t$'\n' -k1.36,1.39 -n animals.txt
donkey Cisco IOS in a Nutshell 2005 Boney, James
horse Linux in a Nutshell 2009 Siever, Ellen
alpaca Intermediate Perl 2012 Schwatz, Randal
# sort numerically by year (descending)
$ sort -t$'\n' -k1.36,1.39 -rn animals.txt
alpaca Intermediate Perl 2012 Schwatz, Randal
horse Linux in a Nutshell 2009 Siever, Ellen
donkey Cisco IOS in a Nutshell 2005 Boney, James
NOTE: assumes all lines have the year in the same position (ie, the contents of the file are formatted per a fixed-width scheme)
Obviously this approach requires we know the position of the year substring in advance; there are a few ways to determine this position ... one idea, assuming the year column will always be the first occurrence of a 4-digit substring ... use bash regex matching and the BASH_REMATCH[] array to determine the length of the line up to the 4-digit year, eg:
$ regex="^([^0-9]*)([0-9]{4}).*"
$ [[ $(head -1 animals.txt) =~ $regex ]] && typeset -p BASH_REMATCH
declare -ar BASH_REMATCH=([0]="alpaca Intermediate Perl 2012 Schwatz, Randal" [1]="alpaca Intermediate Perl " [2]="2012")
From this we see that the BASH_REMATCH[1] contains the contents of the line up to the year (2012 for the alpaca line); now we grab the length of BASH_REMATCH[1] and add 1/ 3 to get our x and y values:
$ (( x = ${#BASH_REMATCH[1]} 1 ))
$ (( y = x 3 ))
$ typeset -p x y
declare -- x="36"
declare -- y="39"
Plugging these variables into our previous sort call:
# sort numerically by year (ascending)
$ sort -t$'\n' -k1.${x},1.${y} -n animals.txt
donkey Cisco IOS in a Nutshell 2005 Boney, James
horse Linux in a Nutshell 2009 Siever, Ellen
alpaca Intermediate Perl 2012 Schwatz, Randal
# sort numerically by year (descending)
$ sort -t$'\n' -k1.${x},1.${y} -rn animals.txt
alpaca Intermediate Perl 2012 Schwatz, Randal
horse Linux in a Nutshell 2009 Siever, Ellen
donkey Cisco IOS in a Nutshell 2005 Boney, James
NOTE: OP hasn't defined a secondary sort requirement in the case of multiple lines having the same date but it shouldn't be too hard to extend this answer to include a secondary (and tertiary?) sort requirement
CodePudding user response:
Try adding a seperator like a comma, as from there you will be able to use the sort command with the -t argument and specify the given field separator.
To find and replace a character with a seperator I would use cat animals.txt | sed {insert the pattern}.
Based on the file you've shared, you could attempt addding the seperator after the first word, and before and after the numerical values.
CodePudding user response:
One way to do it is to copy the year to the start of each line with sed, sort the resulting output numerically, and then remove the year at the start of each line:
sed 's/^.*[[:space:]]\([12][09][0-9][0-9]\)[[:space:]].*$/\1 &/' animals.txt \
| sort -n | sed 's/^.....//'
The output with the example animals.txt in the question is:
oryx Writing Word Macros 1999 Roman, Steven
donkey Cisco IOS in a Nutshell 2005 Boney, James
snail SSH, The Secure Shell 2005 Barrett, Daniel
horse Linux in a Nutshell 2009 Sievers, Ellen
python Programming Python 2010 Lutz, Mark
alpaca Intermediate Perl 2012 Schwartz, Randal
robin MySQL High Availability 2014 Bell, Charles
CodePudding user response:
If GNU awk is available we can have awk find the index for the year substring and then sort the output for us.
Sample input:
$ cat animals.txt
1 2 3 4 5 6
123456789012345678901234567890123456789012345678901234567890
alpaca Intermediate Perl 2012 Schwatz, Randal
donkey Cisco IOS in a Nutshell 2005 Boney, James
horse Linux in a Nutshell 2009 Siever, Ellen
Where:
- the first 2 lines (the scale) do not exist in the file; the scale shows us ...
- the
yearpart of the line runs from position36to39
One GNU awk idea:
awk '
FNR==1 { x=match($0, /[0-9]{4}/) } # find index of the "year" substring in the 1st line of input; assumes the "year" is the 1st occurrence of a 4-digit substring
{ arr[substr($0,x,4)][FNR]=$0 } # populate 2-dimensional array using "year" and row number (FNR) as indexes
END { PROCINFO["sorted_in"]="@ind_num_asc" # sort indexes as numbers in "asc"ending order
for (i in arr)
for (j in arr[i])
print arr[i][j]
}
' animals.txt
This generates:
donkey Cisco IOS in a Nutshell 2005 Boney, James
horse Linux in a Nutshell 2009 Siever, Ellen
alpaca Intermediate Perl 2012 Schwatz, Randal
If we change the sort order from @ind_num_asc to @ind_num_desc we can generate the output in descending year order, ie:
alpaca Intermediate Perl 2012 Schwatz, Randal
horse Linux in a Nutshell 2009 Siever, Ellen
donkey Cisco IOS in a Nutshell 2005 Boney, James
NOTES:
GNU awkrequired for multi-dimensional array (aka array of arrays) supportGNU awkrequired for thePROCINFO["sorted_in"]feature- assumes the entire file can fit into memory (due to storing all lines in the array)