I encounter a weird problem in Python Pandas, while I read a excel and replace a character "k", the result gives me NaN for the rows without "K". see below image
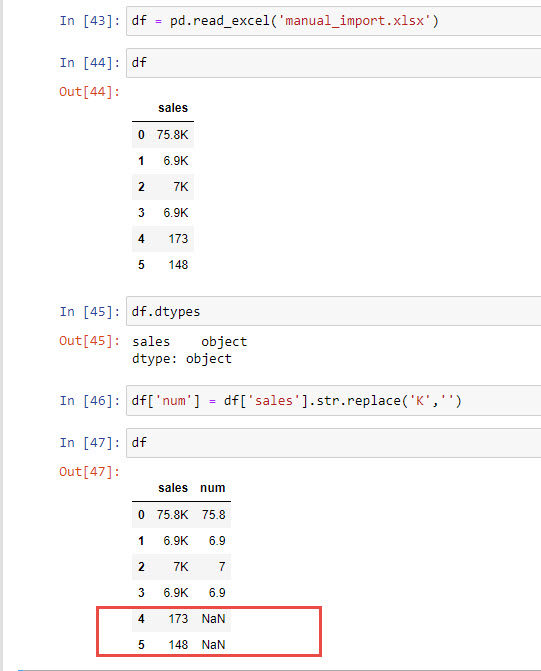
It should return 173 on row #4,instead of NaN, but if I create a brand new excel, and type the same number. it will work.
or if i use this code,
df = pd.DataFrame({ 'sales':['75.8K','6.9K','7K','6.9K','173','148']})
df
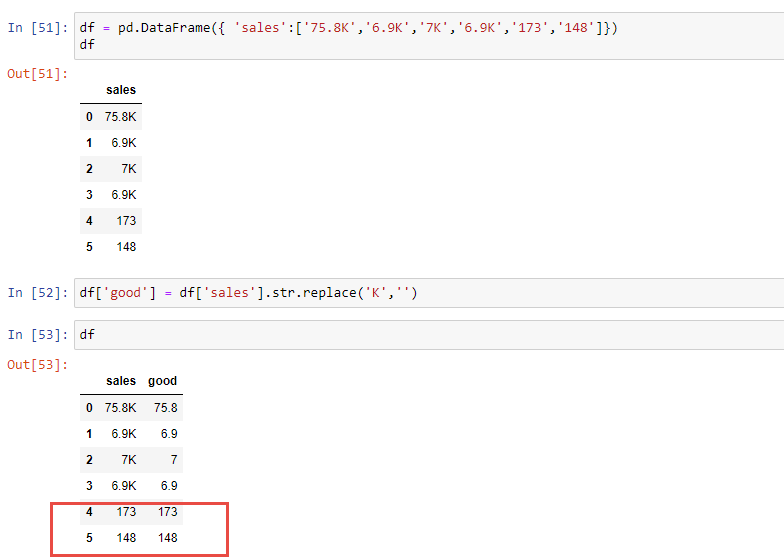
then it will works well. Why? please advise!
CodePudding user response:
This is because the 173 and 148 values from the excel import are numbers, not strings. Since str.replace returns a value that is non-numeric, these values become NaN. You can see that demonstrated by setting up the dataframe with numbers in those position:
df = pd.DataFrame({ 'sales':['75.8K','6.9K','7K','6.9K',173,148]})
df.dtypes
# sales object
# dtype: object
df['num'] = df['sales'].str.replace('K','')
Output:
sales num
0 75.8K 75.8
1 6.9K 6.9
2 7K 7
3 6.9K 6.9
4 173 NaN
5 148 NaN
If you don't mind all your values being strings, you can use
df = pd.read_excel('manual_import.xlsx', dtype=str)
or
df = pd.read_excel('manual_import.xlsx', converters={'sales':str})
should just convert all the sales values to strings.
CodePudding user response:
Try this:
df['nums'] = df['sales'].astype(str)
df['nums'] = pd.to_numeric(df['nums'].str.replace('K', ''))