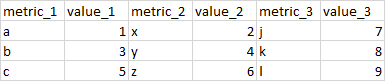
I have the following table:
df = pd.DataFrame(
{
'metric_1': {0: 'a', 1: 'b', 2: 'c'},
'value_1': {0: 1, 1: 3, 2: 5},
'metric_2': {0: 'x', 1: 'y', 2: 'z'},
'value_2': {0: 2, 1: 4, 2: 6},
'metric_3': {0: 'j', 1: 'k', 2: 'l'},
'value_3': {0: 7, 1: 8, 2: 9}
})
I am trying to melt the table so it looks like this instead:
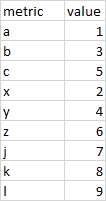
I have tried using melt as follows:
pd.melt(
df,
id_vars=['metric_1', 'metric_2', 'metric_3'],
value_vars=['value_1', 'value_2', 'value_3']
)
but end up something completely different.
Thank you in advance for any help I may receive on this. I'm also open to solutions via Pyspark.
CodePudding user response:
Use pd.wide_to_long, you are trying to do simultaneous melting:
pd.wide_to_long(df.reset_index(), ['metric', 'value'], 'index', 'No', '_', '\d ')
Output:
metric value
index No
0 1 a 1
1 1 b 3
2 1 c 5
0 2 x 2
1 2 y 4
2 2 z 6
0 3 j 7
1 3 k 8
2 3 l 9
CodePudding user response:
You can use stack with some column manipulation.
df.columns = df.columns.str.split("_", expand=True)
df.stack() # .sort_index(level=1) if you care about that
metric value
0 1 a 1
2 x 2
3 j 7
1 1 b 3
2 y 4
3 k 8
2 1 c 5
2 z 6
3 l 9