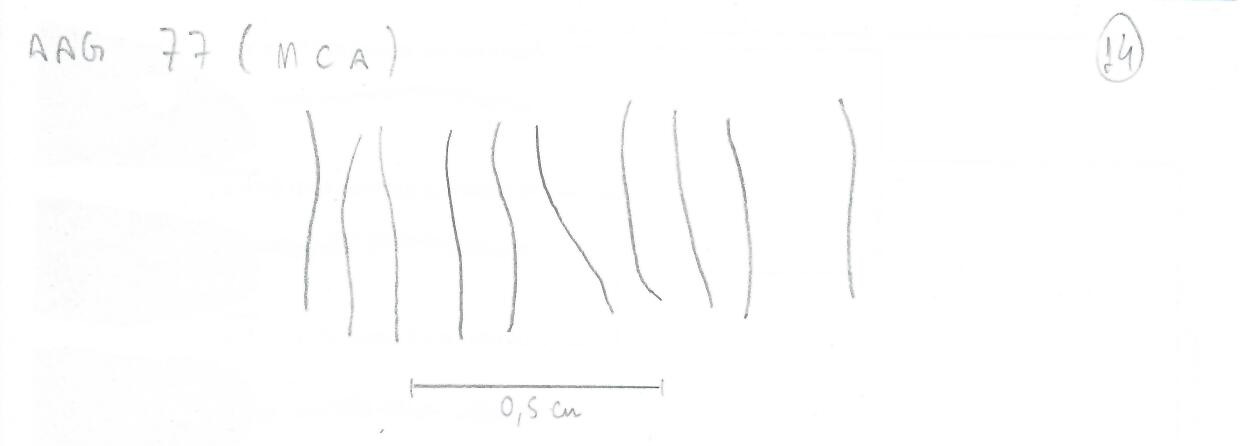
I am trying to automate the measurement of several curved lines based on a scale (see the example image). I have several images like the example one that I have to extract the measurement of each line. I have managed to binarize the image and have been searching for a solution with opencv in python. The procedure that I thought the algorithm should follow is something like:
- binarize the image
- find the scale and set it for measurements
- identify lines to be measured
- measure lines based on scale
- store measurements in a dataframe
I am newbie with programming and been thinking in doing it with python. Should I apply a machine learning algorithm to segment each region containing each line and get their measurement? Or is there a simpler and more intuitive way of doing it without having to train a ML algorithm?
CodePudding user response:
You probably want to break apart the curves into line segments. From there you can measure the length of each line segment to get the total length of the line. That'll give you the length in pixels. You can then convert from pixels to distance by using the scale you provided.
If you don't mind doing the process manually you can use tools like imageJ.
To automate finding the line segments you can try different ways even with opencv. Such as
If you segment each segment you can use contour detection to count the distance around.
CodePudding user response:
I wrote a code mostly following up the fmw42 suggestions and borrowing some ideas of plantcv:
I first set up a custom class to get filename from image since opencv read img as a np.array:
#define a custom class to read filename from cv.imread
class MyImage:
def __init__(self, img_name):
self.img = cv.imread(img_name, cv.IMREAD_GRAYSCALE)
self.__name = img_name
def __str__(self):
return self.__name
Then I got scale calibration (I manually cropped the image to isolate only the scale):
def scale_calibration(img):
#read img
scale = cv.imread(img, cv.IMREAD_GRAYSCALE)
#invert background
scale = 255 - scale
#binarize img
_, scale_bin = cv.threshold(scale, 40, 255, cv.THRESH_BINARY)
#get bounding rectangle to get width of the scale
x, y, w, h = cv.boundingRect(scale_bin)
#define calibration (known distance / distance in pixels of scale)
calibration = 0.5 / w
#plot bounding rectangle to debug
plt.imshow(cv.rectangle(scale, cv.boundingRect(scale_bin), (255, 255, 0), 2))
return calibration
And after that I processed the image containing the curved lines and got their measurements based on the scale calibration:
def fiberLen(img, calibration, plot = True):
#read img
fiber = MyImage(img)
#store filename
filename = str(img)
#invert background to get white pixels on black background
fiber = 255 - fiber.img
#dilate then erode to connect disconnected pixels
fiber = cv.dilate(fiber, None, iterations = 1)
fiber = cv.erode(fiber, None, iterations = 1)
#threshold image
_, fiber_bin = cv.threshold(fiber, 40, 255, cv.THRESH_BINARY)
#binarize img transforming pixel values to 0s and 1s
height, width = fiber_bin.shape
for i in range(height):
for j in range(width):
fiber_bin[i][j] = 1 if fiber_bin[i][j] == 255 else 0
#skeletonize img
fiber_skel = pcv.morphology.skeletonize(fiber_bin) #pcv skeletonize returns 0 and 1 img / skimage skel returns True and False values
#get contours
contours, hierarchy = cv.findContours(fiber_skel, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
#get only contours of fibers (which usually will be greater than 200)
fiber_contours = [c for c in contours if cv.arcLength(c, False) > 200]
#initialize lists to store variables
measurement = []
label_coord_x = []
label_coord_y = []
#get contour perimeter, divide it by 2 and multiply by calibration factor
for i, cnt in enumerate(fiber_contours):
measurement.append(float(cv.arcLength(fiber_contours[i], False) / 2) * calibration)
#get coordinates if plot is True
if plot is True:
label_coord_x.append(fiber_contours[i][0][0][0]) #get first pixel of contours
label_coord_y.append(fiber_contours[i][0][0][1]) #get second pixel of contours
#plot fiber measurements if plot is True
if plot is True:
fiber_copy = fiber.copy()
#loop through measurement values
for i, value in enumerate(measurement):
text = "{:.2f}".format(value)
x = label_coord_x[i]
y = label_coord_y[i]
#put measurement labels in image
cv.putText(fiber_copy, text = text, org = (x, y),
fontFace = cv.FONT_HERSHEY_SIMPLEX,
fontScale = 1,
color = (150, 150, 150),
thickness = 2)
plt.imshow(fiber_copy)
return [filename, measurement]
One issue that showed up is that since the scale in my image is approximately the same size of the lines, the algorithm is also considering the scale in the measurements, as per the image below:
{kind=link}
Any thoughts on how to isolate only the curved lines and disconsider the scale? Also, suggestions on my code to improve performance are welcome.