dt = {'ID': [1, 1, 1, 1, 2, 2, 2, 2],
'Test': [‘Math’, 'Math', 'Writing', 'Writing', ‘Math’, 'Math', 'Writing', 'Writing', ‘Math’]
'Year': ['2008', '2009', '2008', '2009', '2008', ‘2009’, ‘2008’, ‘2009’],
'Fall': [15, 12, 22, 10, 12, 16, 13, 23]
‘Spring’: [16, 13, 22, 14, 13, 14, 11, 20]
‘Winter’: [19, 27, 24, 20, 25, 21, 29, 26]}
mydt = pd.DataFrame(dt, columns = ['ID', ‘Test’, 'Year', 'Fall', ‘Spring’, ‘Winter’])
So I have the above dataset. How can I convert the above dataset so that it looks like the following? Please let me know.
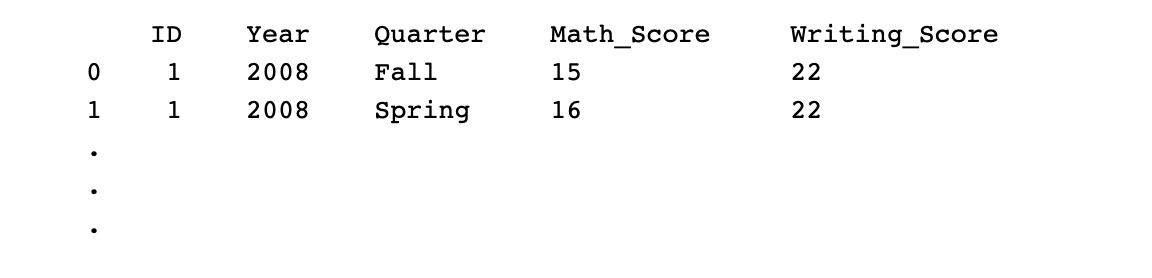
CodePudding user response:
You can try with set_index with stack unstack
out = (df.set_index(['ID','Test','Year']).
stack().unstack(level=1).
add_suffix('_Score').reset_index())
out
Out[271]:
Test ID Year level_2 Math_Score Writing_Score
0 1 2008 Fall 15 22
1 1 2008 Spring 16 22
2 1 2008 Winter 19 24
3 1 2009 Fall 12 10
4 1 2009 Spring 13 14
5 1 2009 Winter 27 20
6 2 2008 Fall 12 13
7 2 2008 Spring 13 11
8 2 2008 Winter 25 29
9 2 2009 Fall 16 23
10 2 2009 Spring 14 20
11 2 2009 Winter 21 26
CodePudding user response:
Here is another solution:
import pandas as pd
data = {'ID': [1, 1, 1, 1, 2, 2, 2, 2],
'Test': ['Math', 'Math', 'Writing', 'Writing', 'Math', 'Math', 'Writing', 'Writing'],
'Year': ['2008', '2009', '2008', '2009', '2008', '2009', '2008', '2009'],
'Fall': [15, 12, 22, 10, 12, 16, 13, 23],
'Spring': [16, 13, 22, 14, 13, 14, 11, 20],
'Winter': [19, 27, 24, 20, 25, 21, 29, 26]}
df_data = pd.DataFrame(data, columns=['ID', 'Test', 'Year', 'Fall', 'Spring', 'Winter'])
df = df_data.melt(id_vars=['ID', 'Year', 'Test'], var_name='Quarter', value_name='Score')
df = df.pivot(index=['ID', 'Year', 'Quarter'], columns=['Test'], values=['Score'])
df.columns = df.columns.droplevel(level=0)
df = df.add_suffix('_Score').reset_index(drop=False)