I have a big dataframe (120000x40) and I try to find duplicates in every row and display them. Thats what I tried:
create dataframe
import pandas as pd
df = pd.DataFrame({'col1':['1-233','2-766g','6-455','4-356','5-253','2-122','5-531','8-345','1-505','3-127','3-622'],
'col2':['6-998','2-766g','5-955','7-236','5-253','7-258','8-987t','7-567','1-505','6-876','NaN'],
'col3':['3-957','NaN','NaN','3-602m','1-266','2-122','7-834','8-345','2-858','7-984g', 'NaN']})
## code
df["duplicate"] = df.apply(lambda x: len(set(x[x.notna()])) != len(x[x.notna()]), axis=1)
print(df)
#output:
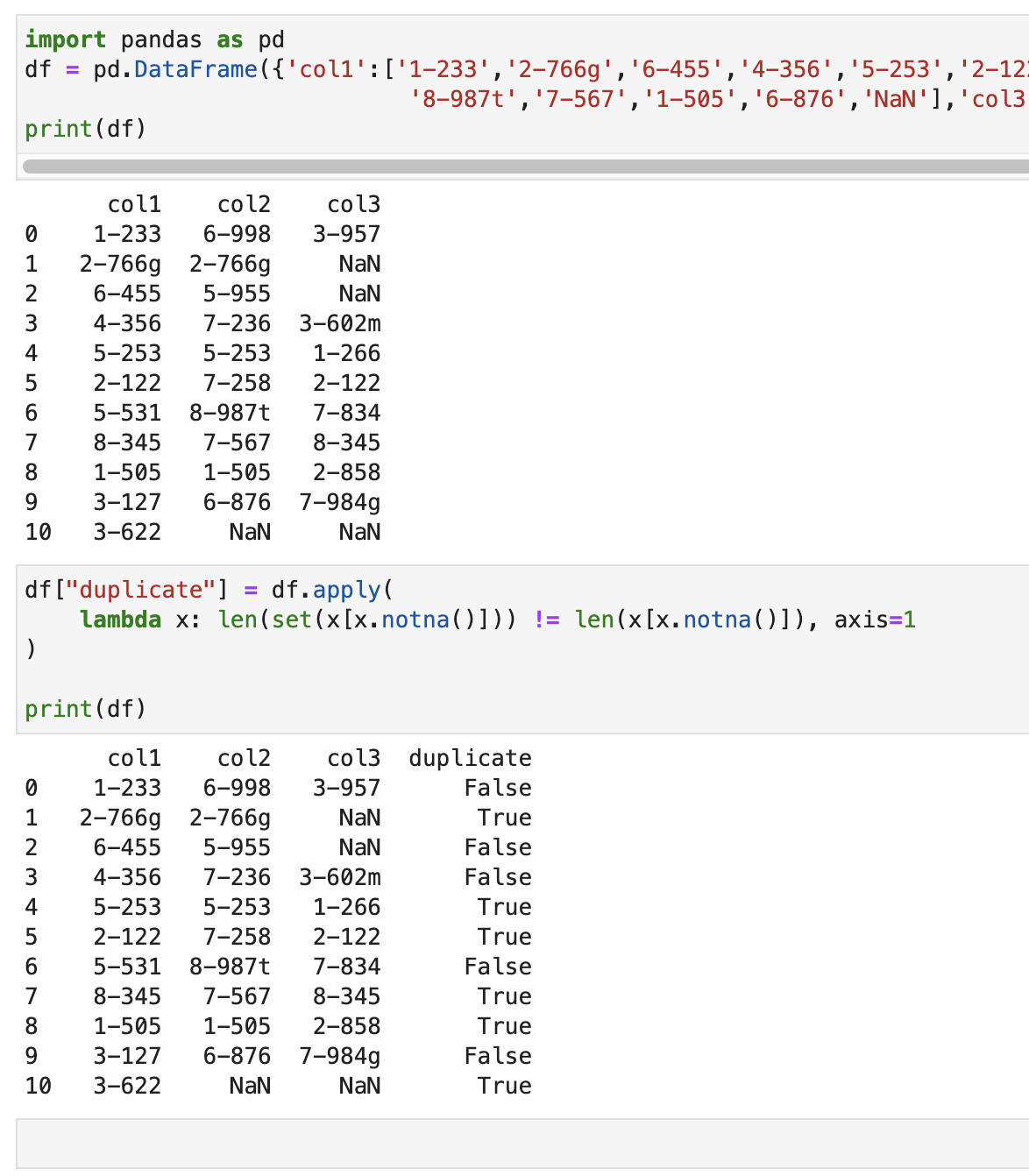
But what I wanted was the folling:
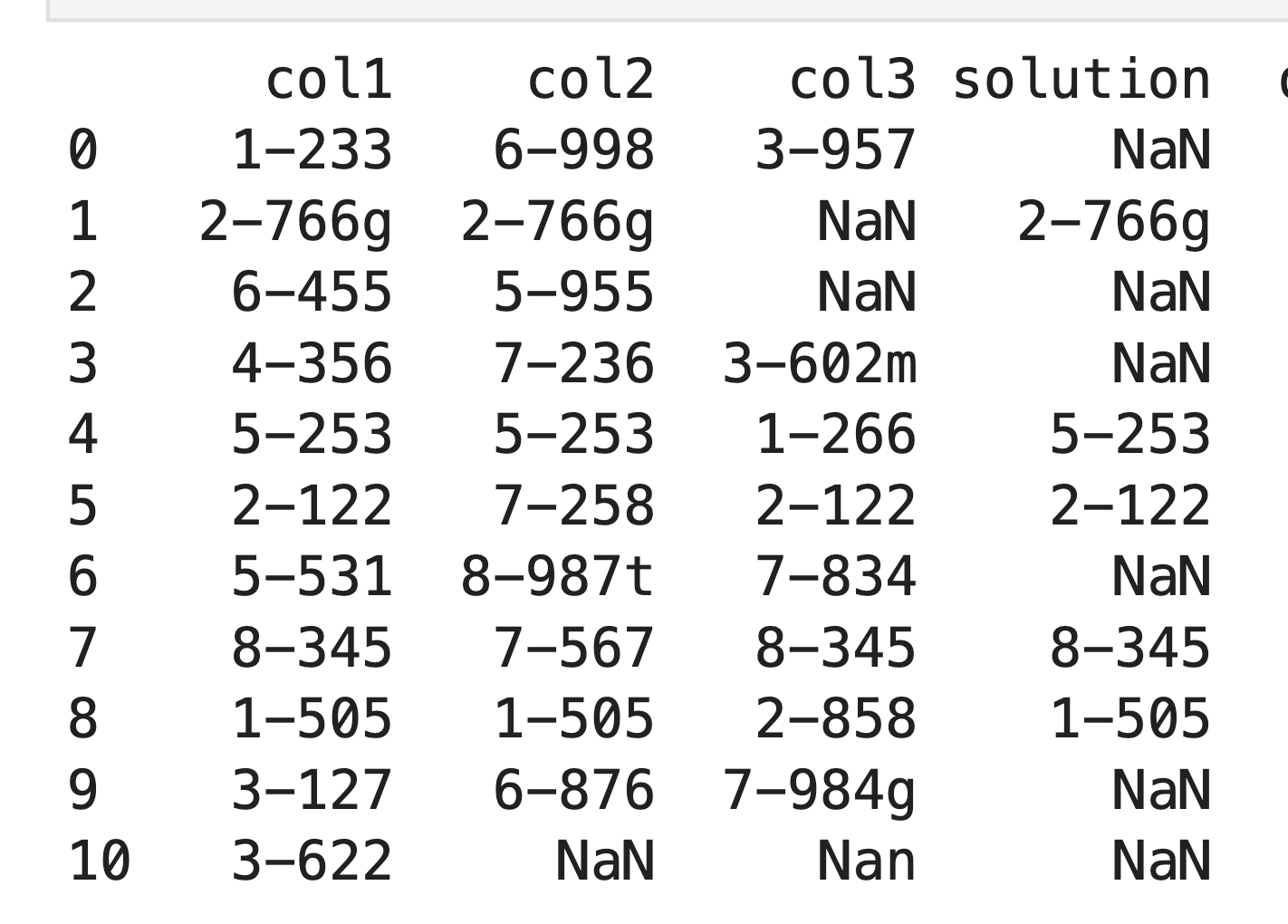 To see what exactly is doubled here.
To see what exactly is doubled here.
CodePudding user response:
To keep the function readable and general, so it works for more or less than three cols, I'd just rely on writing a dedicated function that uses pandas built in functionality for finding duplicates, and applying that to the dataframe rows:
import numpy as np
import pandas as pd
df = pd.DataFrame({'col1':['1-233','2-766g','6-455','4-356','5-253','2-122','5-531','8- 345','1-505','3-127','3-622'],
'col2':['6-998','2-766g','5-955','7-236','5-253','7-258','8-987t','7-567','1-505','6-876','NaN'],
'col3':['3-957','NaN','NaN','3-602m','1-266','2-122','7-834','8-345','2-858','7-984g', 'NaN']})
def get_duplicate_value(row):
"""If row has duplicates, return that value, else NaN."""
duplicate_locations = row.duplicated()
if duplicate_locations.any():
dup_index = duplicate_locations.idxmax()
return row[dup_index]
return np.NaN
df["solution"] = df.apply(get_duplicate_value, axis=1)
Check out the docs of pd.Dataframe.apply, pd.Series.duplicated, pd.Series.any and pd.Series.idxmax to figure out how this works exactly.
Output:
col1 col2 col3 solution
0 1-233 6-998 3-957 NaN
1 2-766g 2-766g NaN 2-766g
2 6-455 5-955 NaN NaN
3 4-356 7-236 3-602m NaN
4 5-253 5-253 1-266 5-253
5 2-122 7-258 2-122 2-122
6 5-531 8-987t 7-834 NaN
7 8- 345 7-567 8-345 NaN
8 1-505 1-505 2-858 1-505
9 3-127 6-876 7-984g NaN
10 3-622 NaN NaN NaN
CodePudding user response:
You can use Nested ternary operator to iterate through your rows and get the duplicate values.
import numpy as np
df['Solution'] = df.apply(lambda row: row.col1 if row.col1 == row.col2 else row.col2 if row.col2 == row.col3 else row.col3 if row.col3 == row.col1 else np.NaN, axis=1)
which gives us the expected output
df
col1 col2 col3 Solution
0 1-233 6-998 3-957 NaN
1 2-766g 2-766g NaN 2-766g
2 6-455 5-955 NaN NaN
3 4-356 7-236 3-602m NaN
4 5-253 5-253 1-266 5-253
5 2-122 7-258 2-122 2-122
6 5-531 8-987t 7-834 NaN
7 8-345 7-567 8-345 8-345
8 1-505 1-505 2-858 1-505
9 3-127 6-876 7-984g NaN
10 3-622 NaN NaN NaN
CodePudding user response:
You could solve this by using Counter from the collections module.
import pandas as pd
import numpy as np
from collections import Counter
df = pd.DataFrame({'col1':['1-233','2-766g','6-455','4-356','5-253','2-122','5-531','8- 345','1-505','3-127','3-622'],
'col2':['6-998','2-766g','5-955','7-236','5-253','7-258','8-987t','7-567','1-505','6-876','NaN'],
'col3':['3-957','NaN','NaN','3-602m','1-266','2-122','7-834','8-345','2-858','7-984g', 'NaN']})
def funct(row):
if Counter(row).most_common(1)[0][1] >= 2:
return Counter(row).most_common(1)[0][0]
return np.nan
df['duplicate'] = df.iloc[:,:3].apply(lambda row: funct(row), axis=1)
print(df)
# N.B. I've changed the entry "8- 345" in `col1` to "8-345"
# (the space appears to be a typo, judging from your prints).
col1 col2 col3 duplicate
0 1-233 6-998 3-957 NaN
1 2-766g 2-766g NaN 2-766g
2 6-455 5-955 NaN NaN
3 4-356 7-236 3-602m NaN
4 5-253 5-253 1-266 5-253
5 2-122 7-258 2-122 2-122
6 5-531 8-987t 7-834 NaN
7 8-345 7-567 8-345 8-345
8 1-505 1-505 2-858 1-505
9 3-127 6-876 7-984g NaN
10 3-622 NaN NaN NaN
E.g. for row 1, Counter(row).most_common(1) will get us: Counter({'2-766g': 2, 'NaN': 1}). We want to check if the first (most common) value >= 2, so Counter(row).most_common(1)[0][1]. If so, the associated key will be your duplicate value. Else, we return np.nan.