I've been taking an algorithm class and so far, the worst-case time complexity for an algorithm all have the same (tight) Big O and Big Omega. Can someone give an example where the two differ? Or explain the importance of these two terms when analyzing the worst-case of an algorithm. I'm struggling to find the point of both of them when it's always the same. Thank you.
CodePudding user response:
These concepts can be quite confusing.
O, Ω and Θ aren't actually tied to worst, best and average time complexities. They just describe relations between functions, or complexity classes.
It is not quite correct to say O describes worst-case, Ω describes best case and Θ describes average. Rather, O describes an upper-bound, Ω a lower bound and Θ describes both at once.
For instance, it is perfectly correct to say that Quicksort has an average time complexity of O(n log n) and a worst-case complexity of O(n2). What is meant is that they are no higher than these complexities.
In short:
- f(n) = O(g(n)) means f(n) is bounded above by g(n). Analogous to ≤.
- f(n) = Ω(g(n)) means f(n) is bounded below by g(n). Analogous to ≥.
- f(n) = Θ(g(n)) means f(n) is bounded both above and below by g(n). Analogous to =.
In practice you often see big-O used when big-Θ could have been more informative. In general, when you publish a new algorithm and you want to claim that it is asymptotically faster than others, you might just say that it has a worst-case time complexity of O(n2) when the previously known fastest algorithm was e.g. O(n3). Everyone then understands that you have found an asymptotically faster algorithm. Maybe it turns out that your algorithm is actually O(n1.99) but it was easier to prove that it was O(n2). Then it is a correct statement because n1.99 = O(n2) but it would not have held true for Θ.
And finally, since you wanted an example of where O and Ω might differ: Quicksort has average time complexity O(n log n). But it is also correct to say it has average time complexity O(n100) because
n log n = O(n100).
Similarly, we can say it is Ω(1) because it is definitely higher or equal to constant-time.
CodePudding user response:
Consider computing the Discrete Fourier Transform of a signal of length N, using the factorization trick: instead of applying a transform of length n.m, with a cost Θ(n.m.N), you decompose in a tranform of length n followed by one of length m, giving the total cost Θ((n m).N). If N is a prime, the complexity is N²; if N is a power of 2, the complexity is N.Lg(N). As these are the extreme cases, we have O(N²) and Ω(N.Lg(N)).
Note: the computations do not depend on the particular sample values, so the given costs are simultaneously best case and worst case for a given N.
Below, the curve of the sum of prime factors (with their multiplicity):
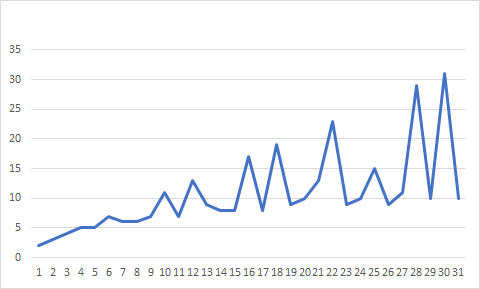
CodePudding user response:
There are 3 measures of time complexity:
- Big O: worst case complexity
- Big theta (Θ): average case complexity (usually when people say big O, they mean big theta)
- Big omega (Ω): best case complexity
Big O >= Big theta >= Big omega
Take quicksort, for example. It will always take at least n log n, where the input is n elements long, so that is the lower bound. It will always take at most n^2, so that is the upper bound. It will usually take n log n, so that is the average case.
So for quicksort, the Big O is O(n^2), Big theta is Θ(n log n), and Big omega is Ω(n log n).
I hope this was helpful.
CodePudding user response:
You are right that the algorithms that we offer classes are generally going to be well-understood algorithms that we can make very precise behavior about. And most will have big-O and big-Omega the same. In fact the fact that they ARE so often the same is why people informally talk about big-O when they really mean big-Theta.
https://stackoverflow.com/a/72998800/585411 offered an excellent example of an important algorithm whose performance jumps around so much depending on n that big-O and big-Omega are very different. But understanding how the FFT works will take some effort. I therefore want to offer a very easy to understand algorithm which has the same property.
Problem, given n find the next prime. Our algorithm in pseudocode will be:
let k = n
let isPrime = true
while not isPrime:
k
isPrime = true
for i in range(2, sqrt(k)):
if 0 == k % 2:
isPrime = false
break
return k
In other words, "Search until we find a number that we prove is prime through trial division." This isn't a particularly efficient algorithm, but it is easy to understand.
The best performance is if the next number is prime. Then this runs in Ω(sqrt(n)). (That requires that the modulo operation is Ω(1). This is true for 64 bit integers but is a big whopping lie for big integer math. I'm also making it a function of n instead of the number of bits needed to represent n. The latter is more usual in analyzing number theory algorithms.)
But what is the worst performance? Well, that is a hard number theory problem. Seriously, start with prime gaps and dig in. But if we just want a limit, we can use Bertrand's postulate to say O(n sqrt(n)). If the Riemann hypothesis is true, we could prove O(n log(n)).
So here we get big-O and big-Omega very different, and (despite the code being simple) we still can't put a precise bound on the big-O.
In your course they'll focus on relatively simple algorithms that are easy to analyze. And I think your implicit point is very good that we should offer examples of algorithms whose performance is all over the map, and which are hard to analyze. Like this one.