I have a pair data as below and I want to make the expected value of the difference in the value (column called value) of pairs. In all the pairs, one has disease and the other one does not have disease as you can see from the data. In other words, the expected value of the difference of the value in one sibling compare to his/her sibling. The description of the variable in the data are:
id = individual ID
family ID = family ID showing their dependency
status = 1 means disease and status = 0 means no-disease
Any guidance is appreciated.
d <- structure(list(id = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20),
familyID = c(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10),
status = c(0,1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1),
value = c(29,26, 39, 22.3, 24, 41, 29.7, 24, 25.9, 21, 29,24,26,29, 15.2, 11, 35, 15.4,16, 13.4)),
class = c("tbl_df","tbl", "data.frame"), row.names = c(NA, -20L))
CodePudding user response:
I'm not certain if this is what you are looking for, but I used pivot_wider from tidyr to spread the values into two columns, though with status 0 and those with status 1. Then I used mutate to take a difference between the two columns, then plotted the familyID by the newly created difference with ggplot. Note that I removed the id column for the pivot_wider to work.
d <- structure(list(id = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20),
familyID = c(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10),
status = c(0,1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1),
value = c(29,26, 39, 22.3, 24, 41, 29.7, 24, 25.9, 21, 29,24,26,29, 15.2, 11, 35, 15.4,16, 13.4)),
class = c("tbl_df","tbl", "data.frame"), row.names = c(NA, -20L))
library(dplyr)
library(tidyr)
library(ggplot2)
d%>%
select(-id)%>%
pivot_wider(values_from = value, names_from = status)%>%
mutate("Diff" = (`0`-`1`))%>%
ggplot()
aes(as.character(familyID), Diff)
geom_point()
CodePudding user response:
You can group by familyID, then use summarize() from the dplyr package to find the differences.
Also note the conversion of id, familyID, and status to factors, which may make life easier so they aren't confused with being integers.
library(dplyr)
library(forcats)
library(ggplot2)
d <- structure(list(id = as.factor(c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20)),
familyID = as.factor(c(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10)),
status = as.factor(c(0,1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1)),
value = c(29,26, 39, 22.3, 24, 41, 29.7, 24, 25.9, 21, 29,24,26,29, 15.2, 11, 35, 15.4,16, 13.4)),
class = c("tbl_df","tbl", "data.frame"), row.names = c(NA, -20L))
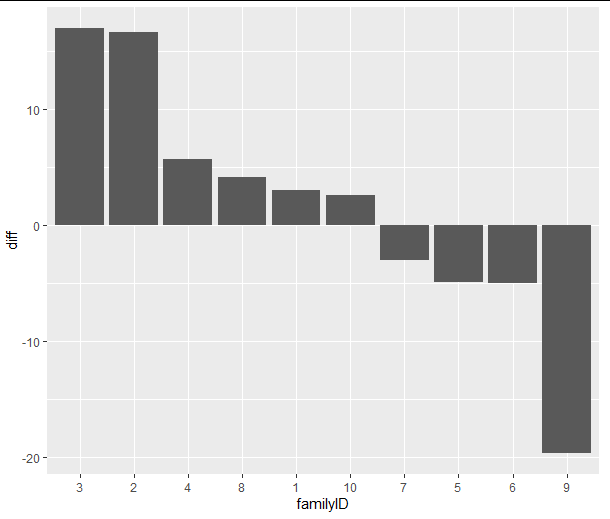
diffs <- group_by(d, familyID) %>%
summarize(., diff = (value[status == 0] - value[status == 1]))
Reordering the families by difference can help get a sense of the distribution of differences
diffs$familyID <- fct_reorder(diffs$familyID, diffs$diff, .desc = TRUE)
ggplot(diffs, aes(x = familyID, y = diff))
geom_bar(stat="identity")
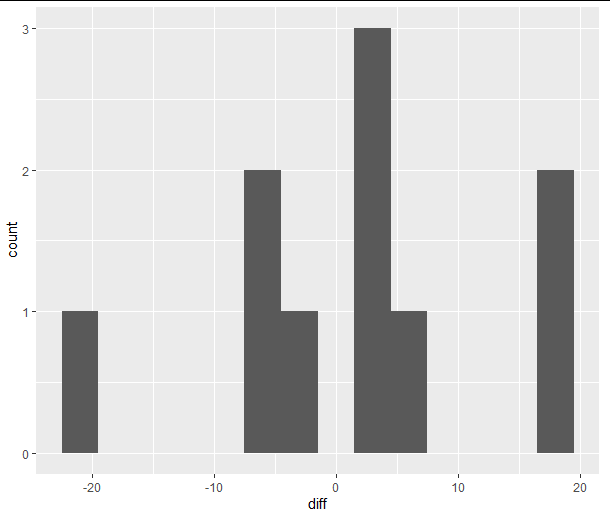
If you really have a lot of families you may want to display a summary of the differences.
One option is with a histogram (modifying binwidth can control how fine the bins are):
ggplot(diffs, aes(x = diff))
geom_histogram(binwidth = 3)
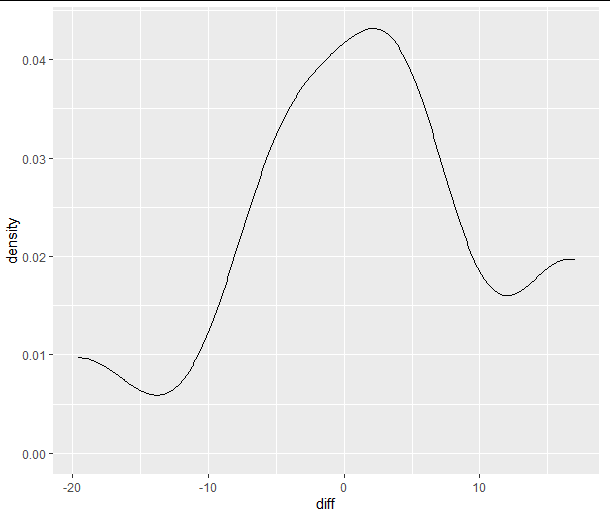
Similar to a histogram is a density plot:
ggplot(diffs, aes(x = diff))
geom_density()
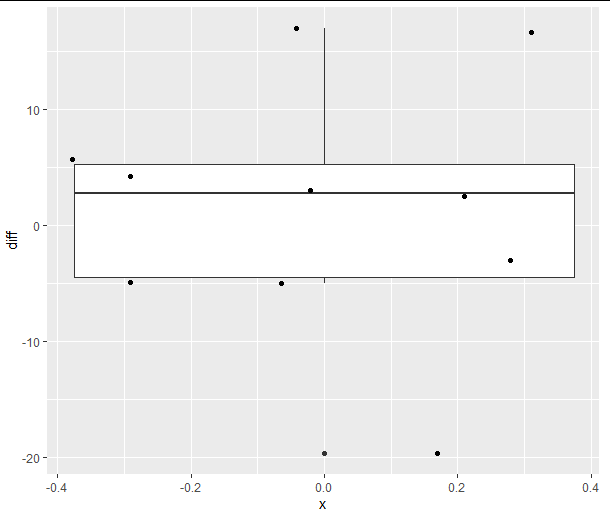
Finally, a boxplot is also a familiar summary. They're mostly meant for comparing multiple groups, but it works okay with just one. I've added the individual points using the geom_jitter() function.
ggplot(diffs, aes(y = diff)) #If using multiple groups add x=group inside the aes() function.
geom_boxplot()
geom_jitter(aes(x = 0))