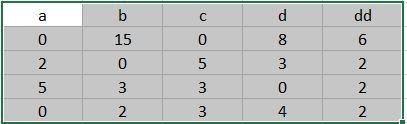
this is my data and i want to find the min value of selected columns(a,b,c,d) in each row then calculate the difference between that and dd. I need to ignore 0 in rows, I mean in the first row i need to find 8
CodePudding user response:
You can use pandas.apply with axis=1 and all column ['a','b','c','d'] convert to Series then replace 0 with inf and find min. At the end compute diff min with colmun 'dd'.
import numpy as np
df['min_dd'] = df.apply(lambda row: min(pd.Series(row[['a','b','c','d']]).replace(0,np.inf)) - row['d'], axis=1)
print(df)
a b c d dd min_dd
0 0 15 0 8 6 2.0 # min_without_zero : 8 , dd : 6 -> 8-6=2
1 2 0 5 3 2 0.0 # min_without_zero : 2 , dd : 2 -> 2-2=0
2 5 3 3 0 2 1.0 # 3 - 2
3 0 2 3 4 2 0.0 # 2 - 2
CodePudding user response:
need to ignore 0 in rows
Then just replace it with nan, consider following simple example
import numpy as np
import pandas as pd
df = pd.DataFrame({"A":[1,2,0],"B":[3,5,7],"C":[7,0,7]})
df.replace(0,np.nan).apply(min)
df["minvalue"] = df.replace(0,np.nan).apply("min",axis=1)
print(df)
gives output
A B C minvalue
0 1 3 7 1.0
1 2 5 0 2.0
2 0 7 7 7.0
CodePudding user response:
You can try
cols = ['a','b','c','d']
df['res'] = df[cols][df[cols].ne(0)].min(axis=1) - df['dd']
print(df)
a b c d dd res
0 0 15 0 8 6 2.0
1 2 0 5 3 2 0.0
2 5 3 3 0 2 1.0
3 2 3 4 4 2 0.0