I'm trying to scraping (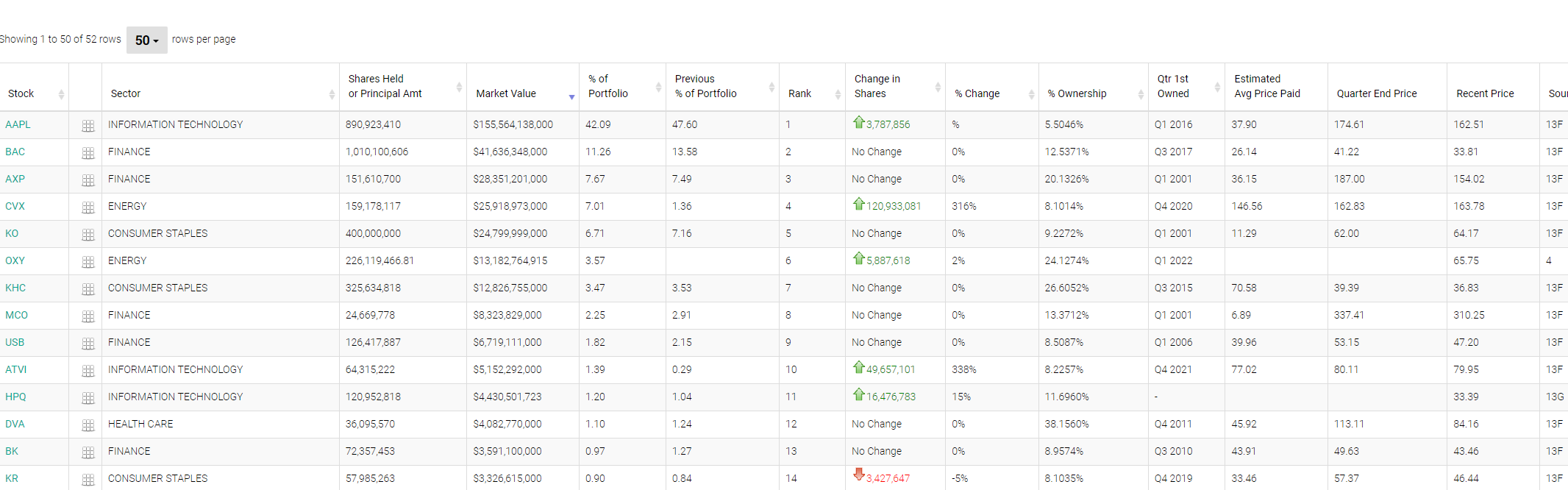
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import pandas as pd
options = webdriver.FirefoxOptions()
options.binary_location = r'C://Mozilla Firefox/firefox.exe'
driver = selenium.webdriver.Firefox(executable_path='C://geckodriver.exe' , options=options)
url = 'https://whalewisdom.com/filer/berkshire-hathaway-inc#tabholdings_tab_link'
driver.get(url)
table = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.ID, 'dgtopHolders')))
dfs = pd.read_html(table.get_attribute('outerHTML'))
print(dfs[0])
How can I scrape this table ?
CodePudding user response:
To scrape the data from the current holdings_table as the <table> is present with the HTML DOM but not visible within the webpage, you need to induce WebDriverWait for the presence_of_element_located() for the <table> element, extract the outerHTML, read the outerHTML using read_html() and you can use the following locator strategy:
Code Block:
driver.execute("get", {'url': 'https://whalewisdom.com/filer/berkshire-hathaway-inc#tabholdings_tab_link'}) # data = driver.find_element(By.CSS_SELECTOR, "table#current_holdings_table").get_attribute("outerHTML") data = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.CSS_SELECTOR, "table#current_holdings_table"))).get_attribute("outerHTML") df = pd.read_html(data) print(df)Console Output:
[ Stock Unnamed: 1 Sector ... Source Source Date Date Reported 0 AAPL NaN INFORMATION TECHNOLOGY ... 13F 2022-03-31 2022-05-16 1 BAC NaN FINANCE ... 13F 2022-03-31 2022-05-16 2 AXP NaN FINANCE ... 13F 2022-03-31 2022-05-16 3 CVX NaN ENERGY ... 13F 2022-03-31 2022-05-16 4 KO NaN CONSUMER STAPLES ... 13F 2022-03-31 2022-05-16 5 OXY NaN ENERGY ... 4 2022-05-02 2022-05-04 6 KHC NaN CONSUMER STAPLES ... 13F 2022-03-31 2022-05-16 7 MCO NaN FINANCE ... 13F 2022-03-31 2022-05-16 8 USB NaN FINANCE ... 13F 2022-03-31 2022-05-16 9 ATVI NaN INFORMATION TECHNOLOGY ... 13F 2022-03-31 2022-05-16 10 HPQ NaN INFORMATION TECHNOLOGY ... 13G 2022-04-30 2022-04-30 11 BK NaN FINANCE ... 13F 2022-03-31 2022-05-16 12 KR NaN CONSUMER STAPLES ... 13F 2022-03-31 2022-05-16 13 DVA NaN HEALTH CARE ... 13D 2022-08-01 2022-08-01 14 C NaN FINANCE ... 13F 2022-03-31 2022-05-16 15 VRSN NaN COMMUNICATIONS ... 13F 2022-03-31 2022-05-16 16 GM NaN CONSUMER DISCRETIONARY ... 13F 2022-03-31 2022-05-16 17 PARA NaN COMMUNICATIONS ... 13F 2022-03-31 2022-05-16 18 CHTR NaN COMMUNICATIONS ... 13F 2022-03-31 2022-05-16 19 LSXMK NaN COMMUNICATIONS ... 13F 2022-03-31 2022-05-16 20 V NaN FINANCE ... 13F 2022-03-31 2022-05-16 21 AMZN NaN CONSUMER DISCRETIONARY ... 13F 2022-03-31 2022-05-16 22 AON NaN FINANCE ... 13F 2022-03-31 2022-05-16 23 MA NaN FINANCE ... 13F 2022-03-31 2022-05-16 24 SNOW NaN INFORMATION TECHNOLOGY ... 13F 2022-03-31 2022-05-16
CodePudding user response:
This is working for me. You can access each element using 'item'.
try:
WebDriverWait(driver, 4).until(EC.presence_of_element_located((By.XPATH, f"/html/body/div[11]/div/div/a/svg")))
except Exception as e:
print(e)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
list_of_tr = WebDriverWait(driver, 4).until(EC.presence_of_all_elements_located((By.XPATH, f"/html/body/div[4]/div[3]/div[1]/fieldset/div[2]/div[1]/div[3]/div[2]/table/tbody/tr")))
for item in list_of_tr:
stock = item.find_element(By.XPATH, './td[1]/a').text.strip()
print(stock)