Basic tables are fairly easy to scrape with Selenium. I am having trouble scraping tables with "_ngcontent" notations ("https://material.angular.io/components/table/overview"). I am trying to scrape it into a dataframe.
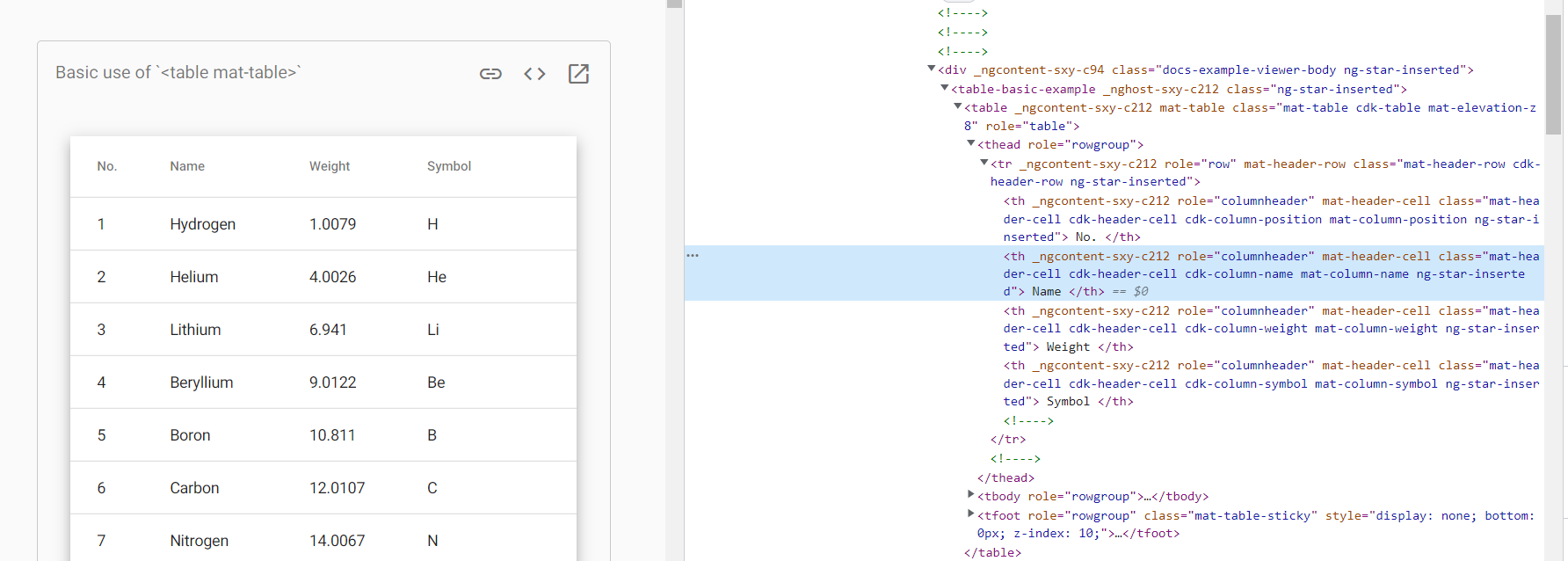
This is how far I got:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pandas as pd
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
PATH = "C:\chromedriver.exe"
driver = webdriver.Chrome(PATH)
URL = 'https://material.angular.io/components/table/overview'
driver.get(URL)
titles = driver.find_element(By.CSS_SELECTOR, '#table-basic > div > div.docs-example-viewer-body.ng-star-inserted > table-basic-example > table > thead')
print(titles.text)
I was only able to get an element with: 'No. Name Weight Symbol' But I am not able to iterate through it, and scrape the data.
Please assist
CodePudding user response:
To grab the table data easily, you can use selenium with pandas
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
table=driver.get('https://material.angular.io/components/table/overview')
driver.maximize_window()
table = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, '(//table)[1]'))).get_attribute("outerHTML")
df = pd.read_html(table)[0]
print(df)
Output:
No. Name Weight Symbol
0 1 Hydrogen 1.0079 H
1 2 Helium 4.0026 He
2 3 Lithium 6.9410 Li
3 4 Beryllium 9.0122 Be
4 5 Boron 10.8110 B
5 6 Carbon 12.0107 C
6 7 Nitrogen 14.0067 N
7 8 Oxygen 15.9994 O
8 9 Fluorine 18.9984 F
9 10 Neon 20.1797 Ne