I'm trying to scrape a website and get every meal_box meal_container row in a list by driver.find_elements but for some reason I couldn't do it. I tried By.CLASS_NAME, because it seemed the logical one but the length of my list was 0. Then I tried By.XPATH, and the length was then 1 (I understand why). I think I can use XPATH to get them one by one, but I don't want to do it if I can handle it in a for loop.
I don't know why the "find_elements(By.CLASS_NAME,'print_name')" works but not "find_elements(By.CLASS_NAME,"meal_box meal_container row")"
I'm new at both web scraping and stackoverflow, so if any other details are needed I can add them.
Here is my code:
meals = driver.find_elements(By.CLASS_NAME,"meal_box meal_container row")
print(len(meals))
for index, meal in enumerate(meals):
foods = meal.find_elements(By.CLASS_NAME, 'print_name')
print(len(foods))
if index == 0:
mealName = "Breakfast"
elif index == 1:
mealName = "Lunch"
elif index == 2:
mealName = "Dinner"
else:
mealName = "Snack"
for index, title in enumerate(foods):
recipe = {}
print(title.text)
print(mealName "\n")
recipe["name"] = title.text
recipe["meal"] = mealName
Here is the screenshot of the HTML:
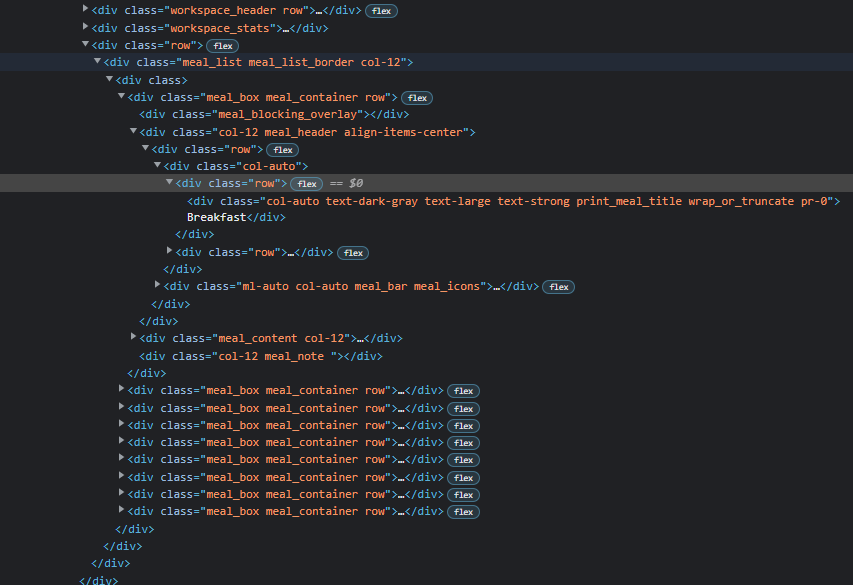
CodePudding user response:
It seems Ok but about class name put a dot between characters. Like "meal_box.meal_container.row" Try this. meals = driver.find_elements(By.CLASS_NAME,"meal_box.meal_container.row")
CodePudding user response:
Try to use driver.find_element_by_css_selector
CodePudding user response:
It can be because "meal_box meal_container row" is inside of other element. So you should try finding the highest element and look for needed one inside.
root = driver.find_element(By.CLASS_NAME,"row")
meals = root.find_elements(By.CLASS_NAME, "meal_box meal_container row")