I would like to perform a query in SQL that will do a groupby if a list contains a common element. For example:
| ID | Groups | Amount |
| -------- | -------------- | -------|
| 1 |[A,B] | 5 |
| 2 |[A,C,D] | 10 |
| 3 |[C,B] | 20 |
So that if I do a GROUP BY on the GROUPS, it will do:
|Groups | AVG(Amount)|
|------ | -----------|
|A | 7.5 |
|B | 12.5 |
|C | 15 |
|D | 10. |
The list lengths are variable.
A few ideas I had are one-hot encoding (expanding along the columns), or duplicate the rows by flattening or using UNNEST, but am not sure the best way to implement. Thanks!
CodePudding user response:
I'm trying to "flatten" an array.
Consider below query:
CREATE TEMP TABLE sample_table AS
SELECT 1 ID, ['A','B'] `Groups`, 5 Amount UNION ALL
SELECT 2, ['A','C','D'], 10 UNION ALL
SELECT 3, ['C','B'], 20;
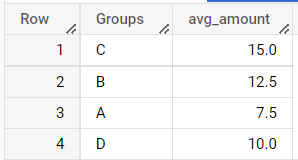
SELECT g AS `Groups`, AVG(Amount) AS avg_amount
FROM sample_table, UNNEST(`Groups`) g
GROUP BY 1;
CodePudding user response:
In your question you did not mention about column that you want group but you are looking for ARRAY_AGG() function.
For example:
WITH vals AS
(
SELECT 1 x, 'a' y UNION ALL
SELECT 1 x, 'b' y UNION ALL
SELECT 2 x, 'a' y UNION ALL
SELECT 2 x, 'c' y
)
SELECT x, ARRAY_AGG(y) as array_agg
FROM vals
GROUP BY x;
---------------
| x | array_agg |
---------------
| 1 | [a, b] |
| 2 | [a, c] |
---------------