My table is like this :
| first | second |
|---|---|
| A | [10,20,30] |
| B | [40,50,60] |
I want to add third column which takes median or mean of the second column, second column's type is string, how can i do in snowflake ?
CodePudding user response:
Assuming that the second column value would always be a string array having three comma separated elements, we could try a regex replacement here:
SELECT first, second, REGEXP_REPLACE(second, '^.*?,|,.*$', '') AS third
FROM yourTable;
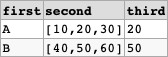
Here is a working demo (given in MySQL 8, but should work equally well on Snowflake).
CodePudding user response:
So if you just want the "middle token" you can use:
With this fake data in a CTE:
with data(first, second) as (
select column1, parse_json(column2)
from values
('A','[10,20,30]'),
('B','[40,50,60]'),
('D','[]'),
('E','[100]'),
('F','[400,500]'),
('G','[400,500,600]'),
('H','[400,500,700,800]'),
('I','[400,500,700,800,900]')
)
this SQL gives:
select d.first
,d.second
,array_size(d.second) as s
,(s/2)::int -1 as p
,d.second[p] as middle_value
from data as d
order by 1;
| FIRST | SECOND | S | P | MIDDLE_VALUE |
|---|---|---|---|---|
| A | [ 10, 20, 30 ] | 3 | 1 | 20 |
| B | [ 40, 50, 60 ] | 3 | 1 | 50 |
| D | [] | 0 | -1 | null |
| E | [ 100 ] | 1 | 0 | 100 |
| F | [ 400, 500 ] | 2 | 0 | 400 |
| G | [ 400, 500, 600 ] | 3 | 1 | 500 |
| H | [ 400, 500, 700, 800 ] | 4 | 1 | 500 |
| I | [ 400, 500, 700, 800, 900 ] | 5 | 2 | 700 |
which can be reformed as:
select d.first
,d.second
,d.second[(array_size(d.second)/2)::int -1] as middle_value
from data as d
order by 1;
Or you can flatten the data, and just use the MEDIAN function:
select d.first
,MEDIAN(f.value) as median_value
from data as d
,table(flatten(input=>d.second)) f
group by d.first, f.seq
order by 1;
with the same CTE gives:
| FIRST | MEDIAN_VALUE |
|---|---|
| A | 20 |
| B | 50 |
| E | 100 |
| F | 450 |
| G | 500 |
| H | 600 |
| I | 700 |
The second form has the merit of allowing other functions to also be used:
select d.first
,MEDIAN(f.value) as median_value
,AVG(f.value) as avg_value
,STDDEV(f.value) as stddev_value
from data as d
,table(flatten(input=>d.second)) f
| FIRST | MEDIAN_VALUE | AVG_VALUE | STDDEV_VALUE |
|---|---|---|---|
| A | 20 | 20 | 10 |
| B | 50 | 50 | 10 |
| E | 100 | 100 | null |
| F | 450 | 450 | 70.710678119 |
| G | 500 | 500 | 100 |
| H | 600 | 600 | 182.574185835 |
| I | 700 | 660 | 207.364413533 |
lastly the D row, as it has no value produces no output, this can be fixed by using the OUTER => TRUE option of FLATTEN
select d.first
,MEDIAN(f.value) as median_value
from data as d
,table(flatten(input=>d.second, outer=>true)) f
group by d.first, f.seq
order by 1;
now D is present:
| FIRST | MEDIAN_VALUE |
|---|---|
| A | 20 |
| B | 50 |
| D | null |
| E | 100 |
| F | 450 |
| G | 500 |
| H | 600 |
| I | 700 |