Issue:
I have two tables with sample inputs below:
Baseline_Cars:
| Name | Fname | FW_Base | Seq | FP_Base | FW_Prop | FP_Prop | isChanged | changeType |
|---|---|---|---|---|---|---|---|---|
| Audi | A1 | 2 | 0 | 2 | 0 | 0 | 0 | "" |
| Audi | A2 | 3 | 0 | 3 | 0 | 0 | 0 | "" |
| Audi | A3 | 4 | 0 | 4 | 0 | 0 | 0 | "" |
| BMW | X1 | 5 | 0 | 5 | 0 | 0 | 0 | "" |
| BMW | X2 | 6 | 0 | 6 | 0 | 0 | 0 | "" |
| Merc | M4 | 7 | 0 | 7 | 0 | 0 | 0 | "" |
| Merc | M5 | 8 | 0 | 8 | 0 | 0 | 0 | "" |
Proposed_Cars:
| 1 | 2 | 3 | 4(FW_Base) | 5(FW_Prop) | 6(FP_Base) | 7(FP_Prop) | 8(isChanged) | 9(changeType) |
|---|---|---|---|---|---|---|---|---|
| 144 | Audi | A1 | 2 | 1 | 1 | 1 | 1 | W |
| 144 | Audi | A2 | 3 | 3 | 3 | 1 | 1 | P |
| 144 | BMW | X1 | 5 | 3 | 3 | 3 | 1 | W |
| 144 | BMW | X2 | 6 | 4 | 4 | 4 | 1 | W |
Expected Solution:
| 1 | 2 | 3 | 4(FW_Base) | 5(FW_Prop) | 6(FP_Base) | 7(FP_Prop) | 8(isChanged) | 9(changeType) |
|---|---|---|---|---|---|---|---|---|
| 144 | Audi | A1 | 2 | 1 | 1 | 1 | 1 | W |
| 144 | Audi | A2 | 3 | 3 | 3 | 1 | 1 | P |
| 144 | Audi | A3 | 4 | 0 | 4 | 0 | 0 | NULL |
| 144 | BMW | X1 | 5 | 3 | 3 | 3 | 1 | W |
| 144 | BMW | X2 | 6 | 4 | 4 | 4 | 1 | W |
Explanation of the expected solution:
Baseline cars contain names of car brands with Fnames, baseline weights(FW_Base),baseline Parameters(FP_Base).
Proposed cars contain names of cars with Proposed new weights(FW_PROP) and new Parameters(FP_PROP).
By default the FW_PROP, FP_PROP, isChanged are 0 in Baseline cars and changeType column is empty string.
isChanged=1 in Proposed cars tells that new weights or parameters have been suggested(if changeType = W, new weight change or changeType=P, new Parameter change)
I wish to merge the tables on the condition that if the Fname in Proposed cars exists in Baseline cars, we substitute the respective columns in Baseline_Cars, along with imputing NULL for changeType incase no change were made. (e.g Audi A3 row)
Snippet code to generate the above sample input data:
baseline_cars = pd.DataFrame(columns=['Name','Fname','FW_Base','Seq','FP_Base','FW_Prop','FP_Prop','isChanged','ChangeType'])
proposed_cars = pd.DataFrame(columns=['1','2','3','4(FW_Base)','5(FW_Prop)','6(FP_Base)','7(FP_Prop)','8(isChanged)','9(ChangeType)'])
baseline_cars = baseline_cars.append({'Name':'Audi','Fname':'A1','FW_Base':2,'Seq':0,'FP_Base':2,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
baseline_cars = baseline_cars.append({'Name':'Audi','Fname':'A2','FW_Base':3,'Seq':0,'FP_Base':3,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
baseline_cars = baseline_cars.append({'Name':'Audi','Fname':'A3','FW_Base':4,'Seq':0,'FP_Base':4,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
baseline_cars = baseline_cars.append({'Name':'BMW','Fname':'X1','FW_Base':5,'Seq':0,'FP_Base':5,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
baseline_cars = baseline_cars.append({'Name':'BMW','Fname':'X2','FW_Base':6,'Seq':0,'FP_Base':6,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
baseline_cars = baseline_cars.append({'Name':'Merc','Fname':'M4','FW_Base':7,'Seq':0,'FP_Base':7,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
baseline_cars = baseline_cars.append({'Name':'Merc','Fname':'M5','FW_Base':8,'Seq':0,'FP_Base':8,'FW_Prop':0,'FP_Prop':0,'isChanged':0,'ChangeType':""}, ignore_index=True)
proposed_cars = proposed_cars.append({'1':144,'2':'Audi','3':'A1','4(FW_Base)':2,'5(FW_Prop)':1,'6(FP_Base)':1,'7(FP_Prop)':1,'8(isChanged)':1,'9(ChangeType)':"W"}, ignore_index=True)
proposed_cars = proposed_cars.append({'1':144,'2':'Audi','3':'A2','4(FW_Base)':3,'5(FW_Prop)':3,'6(FP_Base)':3,'7(FP_Prop)':1,'8(isChanged)':1,'9(ChangeType)':"P"}, ignore_index=True)
proposed_cars = proposed_cars.append({'1':144,'2':'BMW','3':'X1','4(FW_Base)':5,'5(FW_Prop)':3,'6(FP_Base)':3,'7(FP_Prop)':3,'8(isChanged)':1,'9(ChangeType)':"W"}, ignore_index=True)
proposed_cars = proposed_cars.append({'1':144,'2':'BMW','3':'X2','4(FW_Base)':6,'5(FW_Prop)':4,'6(FP_Base)':4,'7(FP_Prop)':4,'8(isChanged)':1,'9(ChangeType)':"W"}, ignore_index=True)
CodePudding user response:
Check Below code, sharing raw data also that is being used for clarity (created it before it was shared in Question)
import pandas as pd
import numpy as np
Baseline_Cars = pd.DataFrame({'Name':['Audi','Audi','Audi','BMW','BMW','Merc','Merc',],
'Fname':['A1','A2','A3','X1','X2','M4','M5',],
'FW_Base':['2','3','4','5','6','7','8',],
'Seq':['0','0','0','0','0','0','0',],
'FP_Base':['2','3','4','5','6','7','8',],
'FW_Prop':['0','0','0','0','0','0','0',],
'FP_Prop':['0','0','0','0','0','0','0',],
'isChanged':['0','0','0','0','0','0','0',],
'changeType':["","","","","","","",]
})
Proposed_Cars = pd.DataFrame({'1':['144','144','144','144',],
'2':['Audi','Audi','BMW','BMW',],
'3':['A1','A2','X1','X2',],
'4(FW_Base)':['2','3','5','6',],
'5(FW_Prop)':['1','3','3','4',],'6(FP_Base)':['1','3','3','4',],
'7(FP_Prop)':['1','1','3','4',],'8(isChanged)':['1','1','1','1',],
'9(changeType)':['W','P','W','W',]})
merged_df = pd.merge(Baseline_Cars,Proposed_Cars, left_on=['Name','Fname'], right_on = ['2','3'], how='left' )
merged_df = merged_df[merged_df['Name'].isin(Proposed_Cars['2'].tolist())]
merged_df = merged_df.drop(['2','3'], axis=1).rename(columns={'Name':'2','Fname':'3'})
common_cols = [(j,i) for j in Proposed_Cars for i in Baseline_Cars if j.find(i)> -1]
merged_df[[i[0] for i in common_cols]] = merged_df.apply(lambda x: ','.join([x[i[1]] if (str(x[i[0]]) == 'nan') else x[i[0]] for i in common_cols]), axis=1).astype('str').str.split(',', expand=True)
merged_df[['1','2','3'] [i[0] for i in common_cols]].ffill().replace('',np.NaN)
Output:
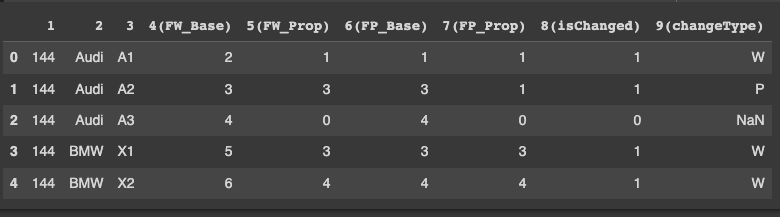
Update - as per OP' comments below, it works with data shared in question
merged_df = pd.merge(baseline_cars,proposed_cars, left_on=['Name','Fname'], right_on = ['2','3'], how='left' )
merged_df = merged_df[merged_df['Name'].isin(proposed_cars['2'].tolist())]
merged_df = merged_df.drop(['2','3'], axis=1).rename(columns={'Name':'2','Fname':'3'})
common_cols = [(j,i) for j in proposed_cars for i in baseline_cars if j.find(i)> -1]
merged_df[[i[0] for i in common_cols]] = merged_df.apply(lambda x: ','.join([ str(x[i[1]]) if (str(x[i[0]]) == 'nan') else str(x[i[0]]) for i in common_cols]), axis=1).astype('str').str.split(',', expand=True)
merged_df[[i[0] for i in common_cols][:-1]] = merged_df[[i[0] for i in common_cols][:-1]].astype('int')
merged_df[['1','2','3'] [i[0] for i in common_cols]].ffill().replace('',np.NaN)