I have generated a csv using a data response from an API call and it is as follow:
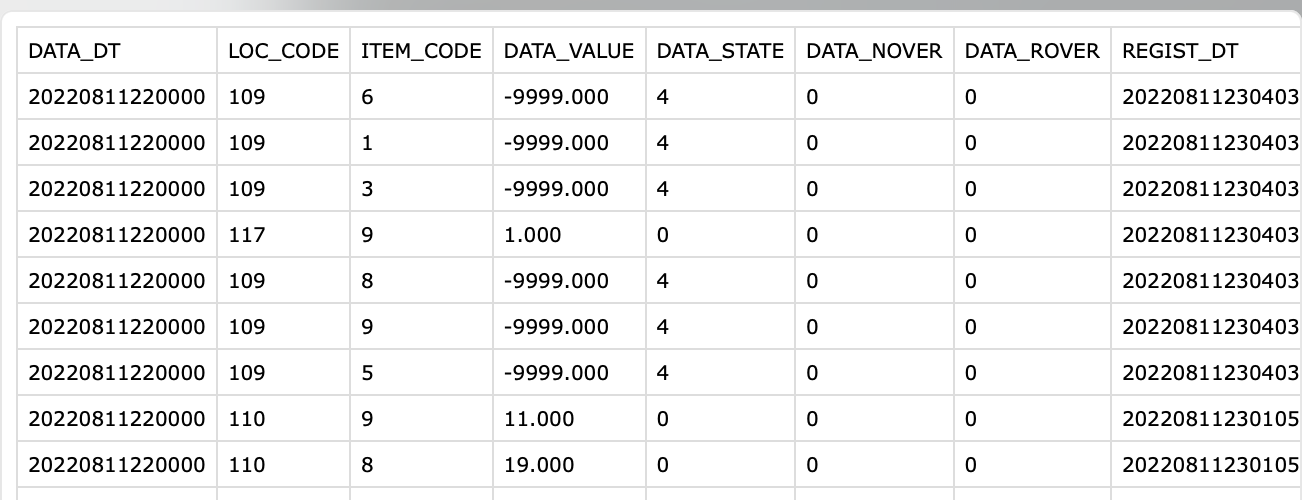
There are a total of 25 LOC_CODE, which means locations.
There are a total of 6 ITEM_CODE, which corresponds to CO2 level, CO level...etc. (I'm gonna map the numeric code to word later but that's not the issue here.)
The item_codes are: 1,3,5,6,8, and 9
The problem:
I want to sort this dataset and overwrite the same csv such that there are only 25 rows where each row is a unique location LOC_CODE.
And I want to display values of all six item_codes per location so it's not one item_code per row like in the screenshot. Everything else stays the same. I just want to display values of all six ITEM_CODE for a unique location on a single row.
I have been looking at methods of converting row to the column using pandas, but all just do it for field names.
The expected output should format as follow: (ignore REGIST_DT, the Date time are from 'DATA_DT')

CodePudding user response:
This solution assumes that the response from the API is already saved into a CSV file in the format given in the first screenshot. I'm using csv.DictReader and csv.DictWriter from the csv module.
Before beginning, let's just import csv using:
import csv
Let's first create a function that'll process the DATA_DT into a desirable format
def get_datetime(value: str):
# returns year, month, day, time (hh:mm:ss), in that order
# assumes string length is 14 and has format 'YYYYMMDDhhmmss'
y, m, d = value[0:4], value[4:6], value[6:8]
t = ':'.join([value[8:10], value[10:12], value[12:14]])
return y, m, d, t
a dictionary for ITEM_CODE:
item_dict = {'1': 'SO2', '3': ...} # please fill this yourself
and the headers list needed for the CSV DictWriter:
headers = ['Location', 'Year', 'Month', 'Day', 'Time (24h)', 'Station No.',
'SO2', 'NO2', 'CO', 'O3', 'PM10', 'PM2.5', 'Meter Status']
We open the CSV file and read from it into a list raw_data (fill the filename, please). Each element of raw_data is a dict:
with open(r'filepath\filename.csv') as file:
raw_data = list(csv.DictReader(file))
We now create an empty dict data, and then iterate over raw_data, processing its data and writing it to the dict (comments added at necessary places):
data = {}
for rec in raw_data:
loc = rec['LOC_CODE']
if loc not in data:
data[loc] = dict.fromkeys(headers, '')
# rec is from old data, record is for the new data
record = data[loc]
if not record['Year']:
# assumed that date & time for a location is same for all ITEM_CODE
(record['Year'],
record['Month'],
record['Day'],
record['Time (24h)']
) = get_datetime(rec['DATA_DT'])
record['Station No.'] = rec['DATA_STATE']
record['Meter Status'] = rec['DATA_NOVER']
# for the readings we get the apt key using item_dict
record[item_dict[rec['ITEM_CODE']]] = rec['DATA_VALUE']
Finally, we arrange all the records in data into a list of dicts the way csv.DictWriter would expect and write it into the output CSV file (please fill in the filename yourself):
records = [{**v, 'Location': k} for k, v in data.items()]
with open(r'filepath\newfilename.csv', 'w') as file:
writer = csv.DictWriter(file, fieldnames=headers, lineterminator='\n')
writer.writeheader()
writer.writerows(records)
(All the ITEM_CODEs that do not have a value in your table will display an empty cell in the created CSV)
You must, of course, tune this code to your requirements - if you want it to not delete existing data from the CSV please change the mode from 'w' to 'a' or 'r ' and modify the data writing part of the code accordingly. And similarly, if you wanna sort the data by date, or whatever, descending, do the same before beginning.
Should I combine all the code into one or leave it to the reader, comment below... ;P