In the below reproducible R code, I'd like to add a column "adjust" that results from a series of calculations that in Excel would use cumulative countifs, max, and match (actually, to make this more complete the adjust column should have used the match formula since there could be more than 1 element in the list starting in row 15, but I think it's clear what I'm doing without actually using match) formulas as shown below in the illustration. The yellow shading shows what the reproducible code generates, and the blue shading shows my series of calculations in Excel that derive the desired values in the "adjust" column. Any suggestions for doing this, in dplyr if possible?
I am a long-time Excel user trying to migrate all of my work to R.
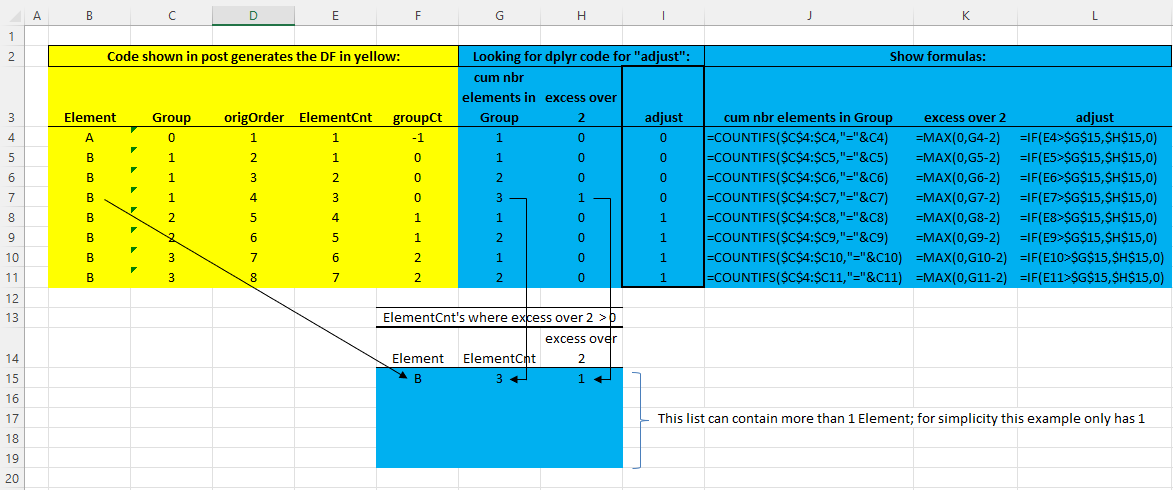
Reproducible code:
library(dplyr)
myData <-
data.frame(
Element = c("A","B","B","B","B","B","B","B"),
Group = c(0,1,1,1,2,2,3,3)
)
myDataGroups <- myData %>%
mutate(origOrder = row_number()) %>%
group_by(Element) %>%
mutate(ElementCnt = row_number()) %>%
ungroup() %>%
mutate(Group = factor(Group, unique(Group))) %>%
arrange(Group) %>%
mutate(groupCt = cumsum(Group != lag(Group, 1, Group[[1]])) - 1L) %>%
as.data.frame()
myDataGroups
CodePudding user response:
We may use rowid to get the sequence to update the 'Group', and then create a logical vector on 'Group' to create the binary and use cumsum on the 'excessOver2' and take the lag
library(dplyr)
library(data.table)
myDataGroups %>%
mutate(Group = rowid(Element, Group),
excessOver2 = (Group > 2), adjust = lag(cumsum(excessOver2),
default = 0))
-output
Element Group origOrder ElementCnt groupCt excessOver2 adjust
1 A 1 1 1 -1 0 0
2 B 1 2 1 0 0 0
3 B 2 3 2 0 0 0
4 B 3 4 3 0 1 0
5 B 1 5 4 1 0 1
6 B 2 6 5 1 0 1
7 B 1 7 6 2 0 1
8 B 2 8 7 2 0 1
CodePudding user response:
library(dplyr)
myData %>%
group_by(Element, Group) %>%
summarize(ElementCnt = row_number(), over2 = 1 * (ElementCnt > 2),
.groups = "drop_last") %>%
mutate(adjust = cumsum(lag(over2, default = 0))) %>%
ungroup()
Result
# A tibble: 8 × 5
Element Group ElementCnt over2 adjust
<chr> <dbl> <int> <dbl> <dbl>
1 A 0 1 0 0
2 B 1 1 0 0
3 B 1 2 0 0
4 B 1 3 1 0
5 B 2 1 0 1
6 B 2 2 0 1
7 B 3 1 0 1
8 B 3 2 0 1