I am evaluating the possibility of reusing ids that have been removed from a column with auto-generated ids. Many records will be deleted per day and we do not want the identifier to exceed 9999.
- Would I have concurrency problems when inserting into the table? (around 100 records would be inserted per day)
- Is there a correct way to reuse ids?
- Should I use another approach to assign this case of ids?
- Should I leave development forever?
I'm just evaluating this possibility. Thank you for your time and experience.
create a table
CREATE TABLE IF NOT EXISTS test(
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
data TEXT);
create function
CREATE OR REPLACE function get_id_test()
returns bigint
language plpgsql
as
$$
DECLARE
min_id bigint;
previous bigint;
next_id bigint;
f record;
BEGIN
SELECT MIN(id) into min_id FROM test;
IF min_id > 1 THEN
RETURN 1;
END IF;
FOR f
IN select t.id from test t order by t.id
LOOP
IF f.id = min_id THEN
previous = f.id;
CONTINUE;
END IF;
IF f.id > (previous 1) THEN
RETURN previous 1;
ELSE
previous = f.id;
END IF;
END LOOP;
next_id = previous 1;
RETURN nextval(pg_get_serial_sequence('test', 'id'));
end;
$$;
insert 5 rows
INSERT INTO test (id,data) VALUES (get_id_test(),'test'),
(get_id_test(),'test'),
(get_id_test(),'test'),
(get_id_test(),'test'),
(get_id_test(),'test');
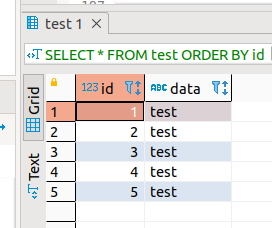
delete 2 rows (2 and 4)
DELETE FROM test WHERE id=2 OR id=4;
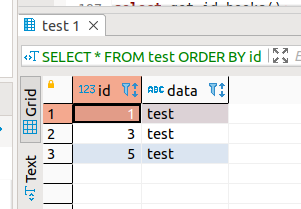
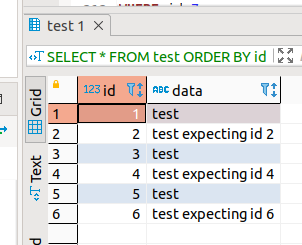
insert row (expecting id=2)
INSERT INTO test (id,data) VALUES (get_id_test(),'test expecting id 2');
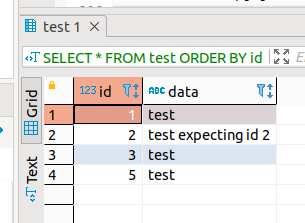
insert row (expecting id=4)
INSERT INTO test (id,data) VALUES (get_id_test(),'test expecting id 4');
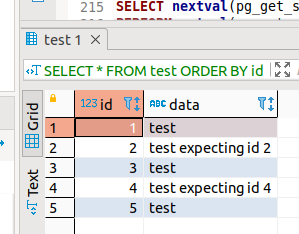
insert row (expecting normal next id from nextval())
INSERT INTO test (id,data) VALUES (get_id_test(),'test expecting id 6');
CodePudding user response:
tl;dr: Don't do it.
You certainly can do it, and transactions will save you. But you're violating assumptions that humans make, and increasing your costs of maintenance and of onboarding new staff to the project.
When I see an autoinc PK, in postgres and other databases, I assume
- monotonic increasing
- therefore "recent" rows have "large" IDs, which makes a difference for physical layout on-disk and for query optimization
- IDs may have been sent out into the world, e.g. appearing in syslog messages, and they mean something
Your hole-filling approach is very very slow. At least use ORDER BY ID DESC, since presumably there's few holes at the bottom and most opportunities are from recent deletions near the top. Consider comparing RANK() to ID so the backend finds a hole without you having to loop looking for it. Most allocators will amortize the cost of a scan by exploiting a cache of scan results.
There is a rich literature on this topic -- start with malloc slab allocators. File systems need to fill holes, also, which Seltzer's "A Comparison of FFS Disk Allocation Policies" briefly touches on.
Consider maintaining a table of at most ten thousand rows which maps integer to either NULL or timestamp last released. A timestamp index would help you quickly find the next unallocated ID. Use old ones or recent ones first, whichever policy you prefer.
You're deliberately limiting the magnitude
of the bigint ID, so int would probably suffice,
saving a little storage.
Consider leaving the PK alone, and define a new integer attribute column where you perform hole-filling to your heart's content.