i have multiple excel files that contains similar information that i want to bring in as list into python with pandas. Every file contains a table that has the info that i want but this table in some files starts at row 5 or in other in row 10 or 23 and go on (because before this table there are some titles that change from one file to others) so this cannot be a constant BUT the headers of the table are the same, can i tell pandas "take all data under the row with "specific name"" ? or have i to tell every time the right index?
Thanks! Have a good work!
Edit: To make it more clear this is how pandas read my dataframe (based on excel file)
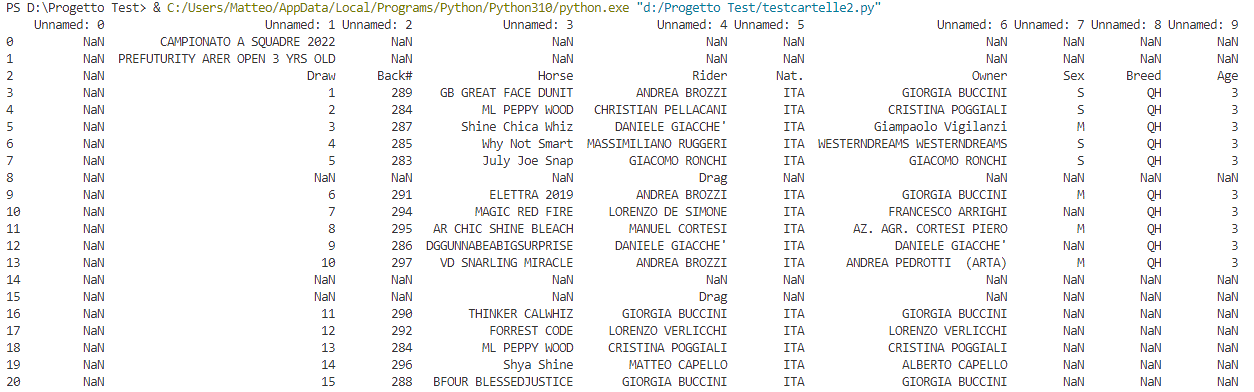
So as you can see in row 2 (in this example) there is the raw with "Draw, Back#,Horse,Rider...) and this is my "keyrow" so i want that my df starts under this row so i can use all below datas to make my folders but as i said this row is the same with all excels but in every excels is in different row.
CodePudding user response:
Since the multiple Excel files have the same column headers, you could create a filter to "take all data under the row with "specific name"".
This can be done using df['col_name']=='specific name' which will return an array of True/False values.
filter = df['col_name']=='specific name'
After that, apply the filter (array of True/False values) to the dataframe, which will keep those values that are True only
df.loc[filter]
For example
df = pd.DataFrame({'col_name': ['nothing', 'specific name', 'specific name', 'blah', 'blah', 'blah'],
'col_2': ['blah blah', 'blah', 'blah blah', 'blah', 'blah', 'blah'] })
col_name col_2
0 nothing blah blah
1 specific name blah
2 specific name blah blah
3 blah blah
4 blah blah
5 blah blah
filter = df['col_name']=='specific name'
print(df.loc[filter])
col_name col_2
1 specific name blah
2 specific name blah blah
CodePudding user response:
With the index, you can use the below code. If you have excel values with row 4 header and from row 5 the rest data
col_name = excel_df.iloc[3:4,:].values.tolist()
df = excel_df.iloc[ 4:,: ]
df.columns = sum(col_name, [])
df