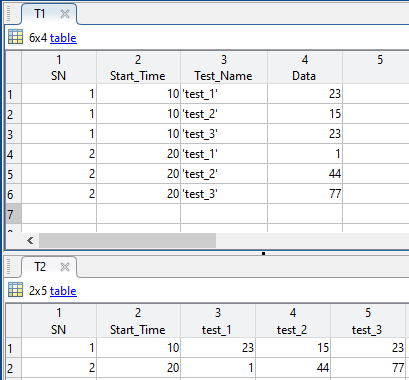
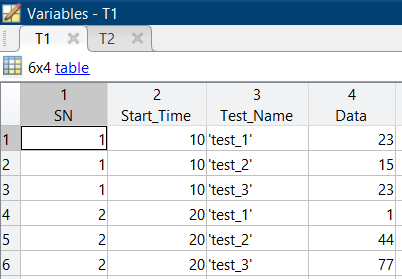
I have a dataset that includes test data for different circuit cards. The original table of data (T1) is orgaized by Serial Number (SN) of the board and a timestamp (Start_Time) that the circuit card started its test procedure. The two remaining columns are the name of the individual test steps (Test_Name) and the data values recoreded at each of those test steps (Data). Since there are multiple tests run for each serial number, the data in SN and Start_Time are duplicated multiple times with the only new information being the Test_Name and Data. You can assume that the Test_Name values are the same for each circuit card serial number (i.e. we can treat them as categorical varriables). I'm looking to do two things:
- Goup the data by SN and Start_Time so they are not duplicated for each test
- append the partially transposed data in Test_Name and Data so that each Test_Name becomes a new variable or column with the appropriate Data value beneath it. Here's a sample of the original data table (T1):
SN = [1; 1; 1; 2; 2; 2];
Start_Time = [10; 10; 10; 20; 20; 20];
Test_Name = {'test_1'; 'test_2'; 'test_3'; 'test_1'; 'test_2'; 'test_3'};
Data = [23; 15; 23; 1; 44; 77];
T1 = table(SN, Start_Time, Test_Name, Data,'VariableNames',{'SN' 'Start_Time' 'Test_Name' 'Data'});
This is what the original data table looks like:
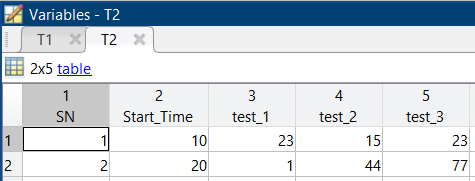
Here's what I'd like the data to look like after it's processed (T2):
CodePudding user response:
You can achieve this with the unstack function
T2 = unstack( T1, 'Data', 'Test_Name' );
This distributes the values in the Data column into multiple columns identified by the value in the Test_Name column. All other columns are preserved as columns in the output. Using your example data we get this output: