I have scraped data from a website using Beautifulsoup, and I want to place it into a Pandas DataFrame and then write it to a file. Most of the data is being written to the file as expected, but some cells are missing values. For example, the first row of the Phone number column is missing a value. The 39th, 45th, and 75th rows of the Postal code column are missing values. Not sure why.
Here is my code:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
schools = "https://www.winnipegsd.ca/page/9258/school-directory-a-z"
page = urlopen(schools)
soup = BeautifulSoup(page,features="html.parser")
table_ = soup.find('table')
Name=[]
Address=[]
PostalCode=[]
Phone=[]
Grades=[]
Website=[]
City=[]
Province=[]
for row in table_.findAll("tr"):
cells = row.findAll('td')
if len(cells)==6:
Name.append(cells[1].find(text=True))
Address.append(cells[4].find(text=True))
PostalCode.append(cells[4].find(text=True).next_element.getText())
Phone.append(cells[5].find(text=True).replace('T: ',''))
Grades.append(cells[2].find(text=True))
Website.append('https://www.winnipegsd.ca' cells[1].findAll('a')[0]['href'])
df = pd.DataFrame(Name,columns=['Name'])
df['Street Address']=Address
df['Postal Code']=PostalCode
df['Phone Number']=Phone
df['Grades']=Grades
df['Website']=Website
df.to_csv("file.tsv", sep = "\t",index=False)
CodePudding user response:
Try pd.read_html() to extract data from table. Then you can do basic .str manipulation:
import requests
import pandas as pd
from bs4 import BeautifulSoup
schools = "https://www.winnipegsd.ca/page/9258/school-directory-a-z"
soup = BeautifulSoup(requests.get(schools).content, "html.parser")
df = pd.read_html(str(soup))[0]
df = df.dropna(how="all", axis=0).drop(columns=["Unnamed: 0", "Unnamed: 3"])
df["Contact"] = (
df["Contact"]
.str.replace(r"T:\s*", "", regex=True)
.str.replace("School Contact Information", "")
.str.strip()
)
df["Postal Code"] = df["Address"].str.extract(r"(.{3} .{3})$")
df["Website"] = [
f'https://www.winnipegsd.ca{a["href"]}'
if "http" not in a["href"]
else a["href"]
for a in soup.select("tbody td:nth-child(2) a")
]
print(df.head(10))
df.to_csv("data.csv", index=False)
Prints:
School Name Grades Address Contact Postal Code Website
0 Adolescent Parent Centre 9-12 136 Cecil St. R3E 2Y9 204-775-5440 R3E 2Y9 https://www.winnipegsd.ca/AdolescentParentCentre/
1 Andrew Mynarski V.C. School 7-9 1111 Machray Ave. R2X 1H6 204-586-8497 R2X 1H6 https://www.winnipegsd.ca/AndrewMynarski/
2 Argyle Alternative High School 10-12 30 Argyle St. R3B 0H4 204-942-4326 R3B 0H4 https://www.winnipegsd.ca/Argyle/
3 Brock Corydon School N-6 1510 Corydon Ave. R3N 0J6 204-488-4422 R3N 0J6 https://www.winnipegsd.ca/BrockCorydon/
4 Carpathia School N-6 300 Carpathia Rd. R3N 1T3 204-488-4514 R3N 1T3 https://www.winnipegsd.ca/Carpathia/
5 Champlain School N-6 275 Church Ave. R2W 1B9 204-586-5139 R2W 1B9 https://www.winnipegsd.ca/Champlain/
6 Children of the Earth High School 9-12 100 Salter St. R2W 5M1 204-589-6383 R2W 5M1 https://www.winnipegsd.ca/ChildrenOfTheEarth/
7 Collège Churchill High School 7-12 510 Hay St. R3L 2L6 204-474-1301 R3L 2L6 https://www.winnipegsd.ca/Churchill/
8 Clifton School N-6 1070 Clifton St. R3E 2T7 204-783-7792 R3E 2T7 https://www.winnipegsd.ca/Clifton/
10 Daniel McIntyre Collegiate Institute 9-12 720 Alverstone St. R3E 2H1 204-783-7131 R3E 2H1 https://www.winnipegsd.ca/DanielMcintyre/
and saves data.csv (screenshot from LibreOffice):
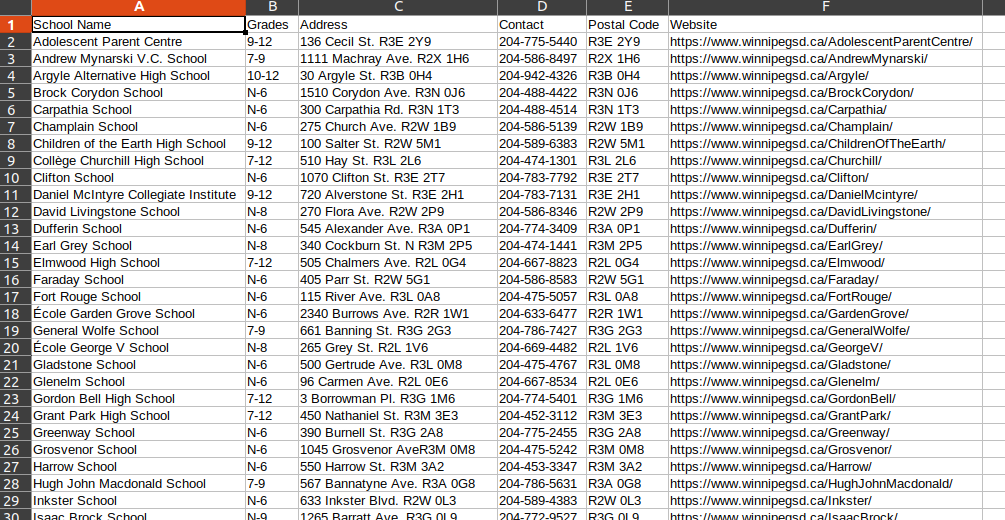
CodePudding user response:
You are getting some missing data value. Becaue they didn't exist in the original/source HTML DOM/table. So if you didn't check then you will get NoneType error and the program will break but you can easily get rid of meaning fix them using if else None statemnt. The following code should work.
import requests
from bs4 import BeautifulSoup
import pandas as pd
schools = "https://www.winnipegsd.ca/page/9258/school-directory-a-z"
page = requests.get(schools).text
soup = BeautifulSoup(page,"html.parser")
data =[]
for row in soup.table.find_all('tr'):
Name = row.select_one('td.ms-rteTableOddCol-6:nth-child(2)')
Name = Name.a.text if Name else None
#print(Name)
Address= row.select_one('td.ms-rteTableEvenCol-6:nth-child(5)')
Address = Address.get_text() if Address else None
#print(Address)
PostalCode=row.select_one('td.ms-rteTableEvenCol-6:nth-child(5)')
PostalCode = PostalCode.get_text().split('.')[-1] if PostalCode else None
#print(PostalCode)
Phone = row.select_one('td.ms-rteTableOddCol-6:nth-child(6)')
Phone = Phone.get_text().split('School')[-2].replace('T:','') if Phone else None
#print(Phone)
Grades= row.select_one('td.ms-rteTableEvenCol-6:nth-child(3)')
Grades = Grades.get_text() if Grades else None
#print(Grades)
Website= row.select_one('td.ms-rteTableOddCol-6:nth-child(2)')
Website= 'https://www.winnipegsd.ca' Website.a.get('href') if Website else None
#print(Website)
data.append({
'Name':Name,
'Address':Address,
'PostalCode':PostalCode,
'Phone':Phone,
'Grades':Grades,
'Website':Website
})
df=pd.DataFrame(data).dropna(how='all')
print(df)
#df.to_csv("file.tsv", sep = "\t",index=False)
Output:
Name ... Website
1 Adolescent Parent Centre ... https://www.winnipegsd.ca/AdolescentParentCentre/
2 Andrew Mynarski V.C. School ... https://www.winnipegsd.ca/AndrewMynarski/
3 Argyle Alternative High School ... https://www.winnipegsd.ca/Argyle/
4 Brock Corydon School ... https://www.winnipegsd.ca/BrockCorydon/
5 Carpathia School ... https://www.winnipegsd.ca/Carpathia/
.. ... ... ...
84 Weston School ... https://www.winnipegsd.ca/Weston/
85 William Whyte School ... https://www.winnipegsd.ca/WilliamWhyte/
86 Winnipeg Adult Education Centre ... https://www.winnipegsd.ca/WinnipegAdultEdCentre/
87 Wolseley School ... https://www.winnipegsd.ca/Wolseley/
88 WSD Virtual School ... https://www.winnipegsd.ca/Virtual/
[79 rows x 6 columns]
CodePudding user response:
The answer by @AndrejKesely is definitely a more pythonic way to handle this case, but you mention in the comments that you are still interested as to why your original method had missing values. Justifiably so! This is where learning how to code should start: by trying to understand why code is failing, well before moving on to a refactored solution.
1. The phone numbers
Let's make some prints:
for row in table_.findAll("tr"):
cells = row.findAll('td')
if len(cells)==6:
# ...
# Phone.append(cells[5].find(text=True).replace('T: ',''))
# ...
print(cells[5].findAll(text=True))
['T:\xa0', '204-775-5440', '\xa0\xa0', 'School Contact Information']
['T: 204-586-8497', '\xa0\xa0', 'School Contact Information', '\xa0']
The problem here is inconsistency in the source code. Open up Chrome DevTools with Ctrl Shift J, right click on any of the phone numbers, and select inspect. You'll move into the "Elements" tab and see how the html is set up. E.g. first two numbers:
ph_no1 = """
<div>
<span>T: </span>
<span lang="EN">204-775-5440
<span> </span>
</span>
</div>
<div> ... School Contact Information </div>
"""
ph_no2 = """
<div>
<span lang="FR-CA">T: 204-586-8497
<span> </span>
</span>
</div>
<div> ... School Contact Information </div>
"""
The aforementioned prints with findAll get you the texts from each span consecutively. I've only shown the first two here, but that's enough to see why you get different data back. So, the problem with the first entry of numbers is that cells[5].find(text=True).replace('T: ','') is only getting us the first text snippet and in the case of ph_no1 this is 'T:\xa0'. For the reason why the replace cannot handle this, see e.g. this SO post.
As it happens, a couple of phone numbers were problematic:
df['Phone Number'][df['Phone Number']\
.str.extract(r'(\d{3}-\d{3}-\d{4})')[0]\
.to_numpy()!=df['Phone Number'].to_numpy()]
0 T:
32 204-783-9012 # 2 extra spaces
33 204-474-1492 # 2 extra spaces
38 204-452-5015 # 2 extra spaces
Suggested solution for the phone numbers. Instead of your code, try getting all the text and extracting a regex pattern that matches the number using re.search:
import re
Phone.append(re.search(r'(\d{3}-\d{3}-\d{4})',cells[5].get_text()).group())
# e.g. \d{3}- means 3 digits followed by "-" etc.
2. The postal code
Problem here is basically the same. Here's an irregular postal code (39th entry), followed by a "regular" one;
pc_error = """
<div>
<span>290 Lilac St. </span>
<br>R3M 2T5
</div>
"""
regular_pc = """
<div>
<span>960 Wolseley Ave. </span>
</div>
<div>
<span>R3G 1E7
</span>
</div>
"""
You wrote:
Address.append(cells[4].find(text=True))
PostalCode.append(cells[4].find(text=True).next_element.getText())
But as you can see above, it turns out that the first example does not actually have a next_element. Now, if you try:
print(len(cells[4].findAll(text=True)))
You'll find that, regardless of the elements, the entire text of each cell will in fact be captured as a list of two strings (['address','postal code']). E.g.:
['511 Clifton St.\xa0', 'R3G 2X3']
['136 Cecil St.\xa0', 'R3E 2Y9']
So, in this particular case, we could simply write:
Address.append(cells[4].findAll(text=True)[0].strip()) # 1st elem and strip
PostalCode.append(cells[4].findAll(text=True)[1].strip()) # 2nd elem and strip
(or again do .get_text() and use a regex pattern; as done by @AndrejKesely).
Hope this helps a bit in clearing up the issues, and suggesting some methods of how to spot unexpected behaviour (prints are always a good friend!).