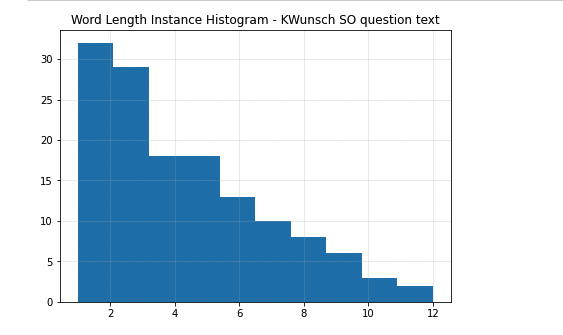
I have the following code:
def composition(tokens, title):
'''creates a curve of composition for a corpus of texts'''
token_lengths = [len(token) for token in tokens]
fig = plt.figure()
plt.gcf().subplots_adjust(bottom=0.15)
len_distr = nltk.FreqDist(token_lengths)
len_distr.plot(25, title=f'{title}')
plt.show()
fig.savefig(f'{title}.png')
it takes the output of a function tokenize as tokens and you have to provide a title for the graph. For example, I tokenize a text with the title and provide the title (longjumeau) in the picture.
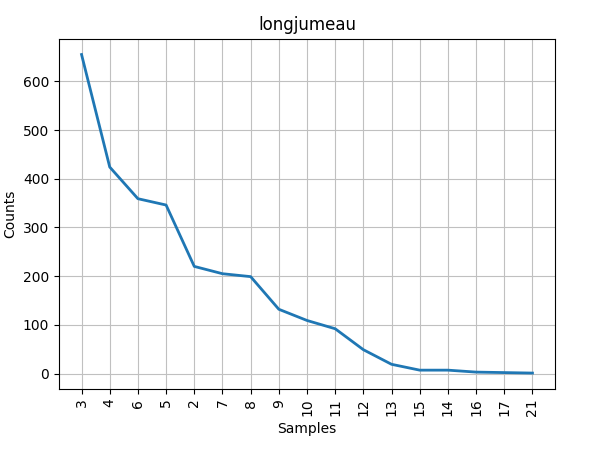
The x-axis is the token-length, i.e. word length (or shortness) sorted after their occurence. So that I can compare different graphs for texts with each other. It might be a bar-diagram, I on't care too much about the kind of the graph at this moment.
Edit, bcs I wasn't too clear about what question I have: How can I order the x-axis values in ascending order (2,3,4,5,6) as opposed to now seemingly being sorted by the highest value on the y-axis.
if further code is needed, this is my git-repo, not perfect code, sorry: