I have a dataset that tracks weight for each option of a multiple choice question which is delineated by column title. This works great, but I need to coalesce the data frame to remove the NA values. How can I do this while maintaining the information stored in the column titles?
The desired output is all the option items coalesced into one column, with a new column called Question that is the column title.
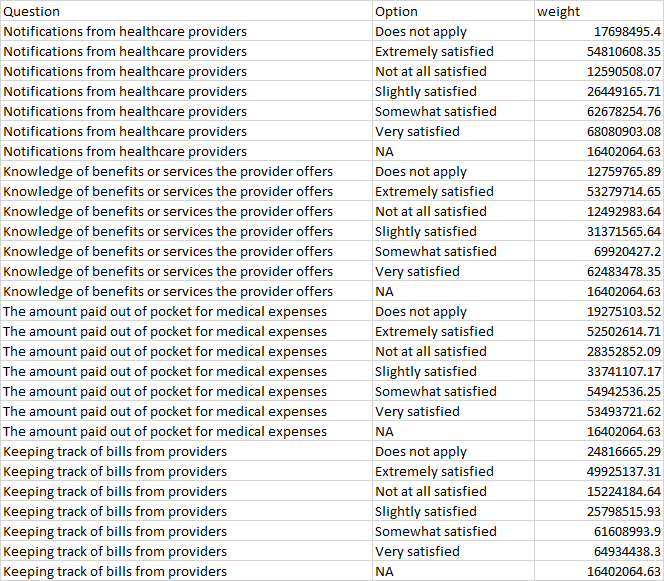
Dput:
structure(list(`Notifications from healthcare providers` = c("Does not apply",
"Extremely satisfied", "Not at all satisfied", "Slightly satisfied",
"Somewhat satisfied", "Very satisfied", NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA), weight = c(17698495.4022986,
54810608.3483721, 12590508.0663396, 26449165.714075, 62678254.7615732,
68080903.0808758, 16402064.6264658, 12759765.8886822, 53279714.6534212,
12492983.6382691, 31371565.642325, 69920427.1996279, 62483478.3512088,
16402064.6264658, 19275103.5161991, 52502614.7148432, 28352852.0938359,
33741107.173015, 54942536.251701, 53493721.62394, 16402064.6264658,
24816665.2917371, 49925137.3115295, 15224184.64181, 25798515.9252893,
61608993.8993347, 64934438.3038336, 16402064.6264658, 36454964.8677938,
48006360.6735044, 16709379.8966983, 24642753.8000864, 59420624.625077,
57073851.5103744, 16402064.6264658, 72967139.5407915, 40009734.2362851,
11804363.6309411, 23014992.772582, 46125385.9778554, 48386319.2150792,
16402064.6264658, 12390214.0452587, 58724950.5941678, 10417785.2977274,
26961484.4682905, 62788313.3718214, 71025187.5962684, 16402064.6264658,
12833673.1505953, 52944095.6227131, 11619183.6511425, 29953067.0398174,
64699359.9044762, 70258556.0047897, 16402064.6264658), `Knowledge of benefits or services the provider offers` = c(NA,
NA, NA, NA, NA, NA, NA, "Does not apply", "Extremely satisfied",
"Not at all satisfied", "Slightly satisfied", "Somewhat satisfied",
"Very satisfied", NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA
), `The amount paid out of pocket for medical expenses` = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "Does not apply",
"Extremely satisfied", "Not at all satisfied", "Slightly satisfied",
"Somewhat satisfied", "Very satisfied", NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA), `Keeping track of bills from providers` = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, "Does not apply", "Extremely satisfied", "Not at all satisfied",
"Slightly satisfied", "Somewhat satisfied", "Very satisfied",
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA), `Options provider offers for over-the-counter healthcare products and medications` = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "Does not apply",
"Extremely satisfied", "Not at all satisfied", "Slightly satisfied",
"Somewhat satisfied", "Very satisfied", NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA
), `Ability to keep track of and/or use HSA/FSA/MSP accounts` = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, "Does not apply", "Extremely satisfied", "Not at all satisfied",
"Slightly satisfied", "Somewhat satisfied", "Very satisfied",
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA),
`The ease of using benefits or services offered by health insurance providers` = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "Does not apply",
"Extremely satisfied", "Not at all satisfied", "Slightly satisfied",
"Somewhat satisfied", "Very satisfied", NA, NA, NA, NA, NA,
NA, NA, NA), `The number of benefits or services the health insurance provider offers` = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, "Does not apply", "Extremely satisfied", "Not at all satisfied",
"Slightly satisfied", "Somewhat satisfied", "Very satisfied",
NA)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-56L))
CodePudding user response:
This is more "pivot and clean-up" than "coalesce".
library(dplyr)
library(tidyr)
pivot_longer(quux, -weight, names_to = "Question", values_to = "Option") %>%
dplyr::filter(!is.na(Option))
# # A tibble: 48 x 3
# weight Question Option
# <dbl> <chr> <chr>
# 1 17698495. Notifications from healthcare providers Does not apply
# 2 54810608. Notifications from healthcare providers Extremely satisfied
# 3 12590508. Notifications from healthcare providers Not at all satisfied
# 4 26449166. Notifications from healthcare providers Slightly satisfied
# 5 62678255. Notifications from healthcare providers Somewhat satisfied
# 6 68080903. Notifications from healthcare providers Very satisfied
# 7 12759766. Knowledge of benefits or services the provider offers Does not apply
# 8 53279715. Knowledge of benefits or services the provider offers Extremely satisfied
# 9 12492984. Knowledge of benefits or services the provider offers Not at all satisfied
# 10 31371566. Knowledge of benefits or services the provider offers Slightly satisfied
# # ... with 38 more rows
See Reshaping data.frame from wide to long format for the pivoting component.