I have a csv file with 2 column store_name and store_location that some store_location is missing. And I want to fill missing data with data in same column based on value in another column.
Below is my csv file:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/hoatranobita/app_to_cloud_4/main/store_location.csv')
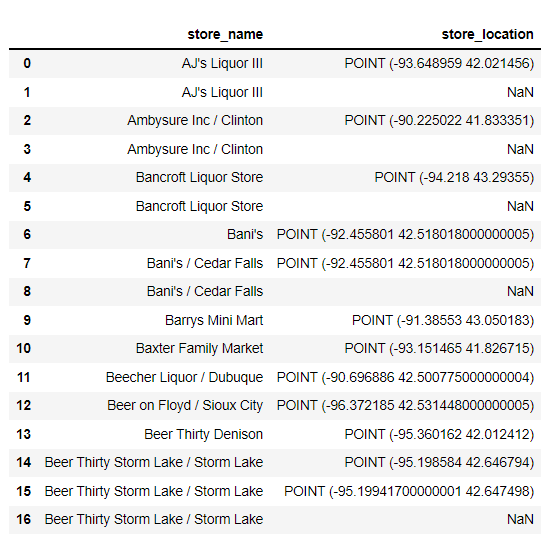
Here is my expected Output:
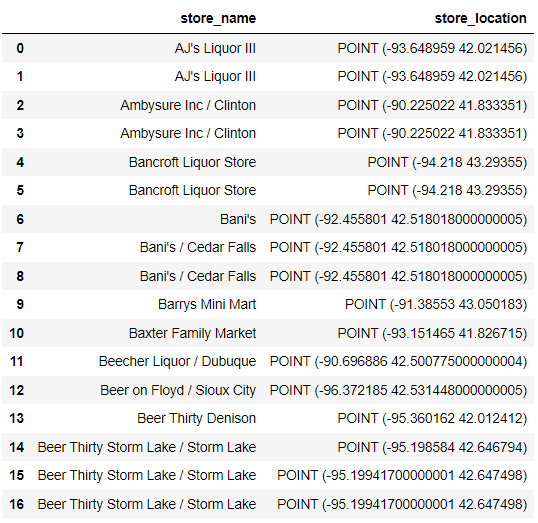
I tried to find solutions but still not find out.
Thanks.
CodePudding user response:
TL;DR: providing 3 different approaches in case you want to:
ensure a unique value per group
fill the NaN with the first available value
fill the NaN with the previous/next non-NA row
Looks like you could need a unique value per group. Use
groupby.transform('first')to get the first non-NA value:
df['store_location'] = df.groupby('store_name')['store_location'].transform('first')
output:
store_name store_location
0 AJ's Liquor III POINT (-93.648959 42.021456)
1 AJ's Liquor III POINT (-93.648959 42.021456)
2 Ambysure Inc / Clinton POINT (-90.225022 41.833351)
3 Ambysure Inc / Clinton POINT (-90.225022 41.833351)
4 Bancroft Liquor Store POINT (-94.218 43.29355)
5 Bancroft Liquor Store POINT (-94.218 43.29355)
6 Bani's POINT (-92.455801 42.518018000000005)
7 Bani's / Cedar Falls POINT (-92.455801 42.518018000000005)
8 Bani's / Cedar Falls POINT (-92.455801 42.518018000000005)
9 Barrys Mini Mart POINT (-91.38553 43.050183)
10 Baxter Family Market POINT (-93.151465 41.826715)
11 Beecher Liquor / Dubuque POINT (-90.696886 42.500775000000004)
12 Beer on Floyd / Sioux City POINT (-96.372185 42.531448000000005)
13 Beer Thirty Denison POINT (-95.360162 42.012412)
14 Beer Thirty Storm Lake / Storm Lake POINT (-95.198584 42.646794)
15 Beer Thirty Storm Lake / Storm Lake POINT (-95.198584 42.646794)
16 Beer Thirty Storm Lake / Storm Lake POINT (-95.198584 42.646794)
- If there are different values and you want to preserve them, you can replace the NaN with the first non-NA value:
df['store_location'] = df['store_location'].fillna(df.groupby('store_name')['store_location'].transform('first'))
output:
store_name store_location
0 AJ's Liquor III POINT (-93.648959 42.021456)
1 AJ's Liquor III POINT (-93.648959 42.021456)
2 Ambysure Inc / Clinton POINT (-90.225022 41.833351)
3 Ambysure Inc / Clinton POINT (-90.225022 41.833351)
4 Bancroft Liquor Store POINT (-94.218 43.29355)
5 Bancroft Liquor Store POINT (-94.218 43.29355)
6 Bani's POINT (-92.455801 42.518018000000005)
7 Bani's / Cedar Falls POINT (-92.455801 42.518018000000005)
8 Bani's / Cedar Falls POINT (-92.455801 42.518018000000005)
9 Barrys Mini Mart POINT (-91.38553 43.050183)
10 Baxter Family Market POINT (-93.151465 41.826715)
11 Beecher Liquor / Dubuque POINT (-90.696886 42.500775000000004)
12 Beer on Floyd / Sioux City POINT (-96.372185 42.531448000000005)
13 Beer Thirty Denison POINT (-95.360162 42.012412)
14 Beer Thirty Storm Lake / Storm Lake POINT (-95.198584 42.646794)
15 Beer Thirty Storm Lake / Storm Lake POINT (-95.19941700000001 42.647498)
16 Beer Thirty Storm Lake / Storm Lake POINT (-95.198584 42.646794)
- Alternatively, use the previous/next non-NA values per group with
ffillbfill:
df['store_location'] = df.groupby('store_name')['store_location'].transform(lambda g: g.ffill().bfill())
output:
store_name store_location
0 AJ's Liquor III POINT (-93.648959 42.021456)
1 AJ's Liquor III POINT (-93.648959 42.021456)
2 Ambysure Inc / Clinton POINT (-90.225022 41.833351)
3 Ambysure Inc / Clinton POINT (-90.225022 41.833351)
4 Bancroft Liquor Store POINT (-94.218 43.29355)
5 Bancroft Liquor Store POINT (-94.218 43.29355)
6 Bani's POINT (-92.455801 42.518018000000005)
7 Bani's / Cedar Falls POINT (-92.455801 42.518018000000005)
8 Bani's / Cedar Falls POINT (-92.455801 42.518018000000005)
9 Barrys Mini Mart POINT (-91.38553 43.050183)
10 Baxter Family Market POINT (-93.151465 41.826715)
11 Beecher Liquor / Dubuque POINT (-90.696886 42.500775000000004)
12 Beer on Floyd / Sioux City POINT (-96.372185 42.531448000000005)
13 Beer Thirty Denison POINT (-95.360162 42.012412)
14 Beer Thirty Storm Lake / Storm Lake POINT (-95.198584 42.646794)
15 Beer Thirty Storm Lake / Storm Lake POINT (-95.19941700000001 42.647498)
16 Beer Thirty Storm Lake / Storm Lake POINT (-95.19941700000001 42.647498)