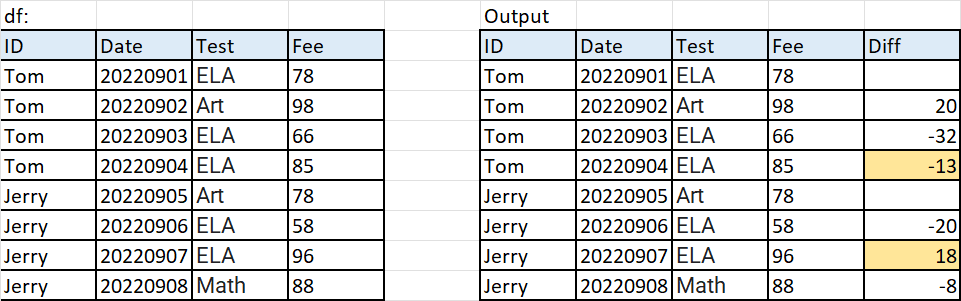
I have a df like below and would like to calculate the fee difference for each ID:
- df %>% arrange (ID, Date) %>% group_by (ID);
Diff= Fee-lag(Fee)whenTest != lag(Test)- if Test== lag(Test), then Diff equal to Fee- Fee from the most closest different Test
The outputs will looks like the one on the right. I am not sure how to get the orange part done. Could anyone guide me on this? Thanks.
df<- structure(list(ID = c("Tom", "Tom", "Tom", "Tom", "Jerry", "Jerry",
"Jerry", "Jerry"), Date = c(20220901, 20220902, 20220903, 20220904,
20220905, 20220906, 20220907, 20220908), Test = c("ELA", "Art",
"ELA", "ELA", "Art", "ELA", "ELA", "Math"), Fee = c(78, 98, 66,
85, 78, 58, 96, 88)), row.names = c(NA, -8L), class = c("tbl_df",
"tbl", "data.frame"))
CodePudding user response:
Based on the expected, we get the difference between the 'Fee' grouped by 'ID' and then get the difference of the absolute in 'Diff' after adding rleid on 'Test' as grouping when there are more than 1 element per group
library(dplyr)
library(data.table)
df %>%
group_by(ID) %>%
mutate(Diff = Fee - lag(Fee)) %>%
group_by(grp = rleid(Test), .add = TRUE) %>%
mutate(Diff = if(n() > 1) c(first(Diff), diff(abs(Diff))) else Diff) %>%
ungroup %>%
select(-grp)
-output
# A tibble: 8 × 5
ID Date Test Fee Diff
<chr> <dbl> <chr> <dbl> <dbl>
1 Tom 20220901 ELA 78 NA
2 Tom 20220902 Art 98 20
3 Tom 20220903 ELA 66 -32
4 Tom 20220904 ELA 85 -13
5 Jerry 20220905 Art 78 NA
6 Jerry 20220906 ELA 58 -20
7 Jerry 20220907 ELA 96 18
8 Jerry 20220908 Math 88 -8