With the help of some very kind people on here I finally got a working script to scrape some data. I now desire to transfer this data from Python to Excel, in a specific format. I have tried multiple approaches, but did not manage to get the desired result.
My script is the following:
import requests
from bs4 import BeautifulSoup
def analyze(i):
url = f"https://ktarena.com/fr/207-dofus-world-cup/match/{i}/1"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
arena = soup.find("span", attrs=('name')).text
title = soup.select_one("[class='team'] .name a").text
point = soup.select(".result .points")[0].text
image_titles = ', '.join([i['title'] for i in soup.select("[class$='dead'] > img")])
title_ano = soup.select("[class='team'] .name a")[1].text
point_ano = soup.select(".result .points")[1].text
image_titles_ano = ', '.join([i['title'] for i in soup.select("[class='class'] > img")])
print((title,point,image_titles),(title_ano,point_ano,image_titles_ano),arena)
for i in range(46270, 46394):
analyze(i)
To summarize, I scrape a couple of things:
- Team names (title & title_ano)
- Image titles (image_titles & image_titles_ano)
- Team points (points & points_ano)
- A string of text (arena)
One line of output currently looks like this:
('Thunder', '0 pts', 'roublard, huppermage, ecaflip') ('Tweaps', '60 pts', 'steamer, feca, sacrieur') A10
My goal is to transfer this output to excel, making it look like this:
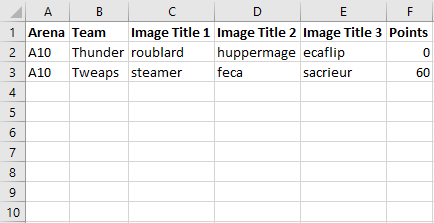
To clarify, in terms of the variables I have it would be this:
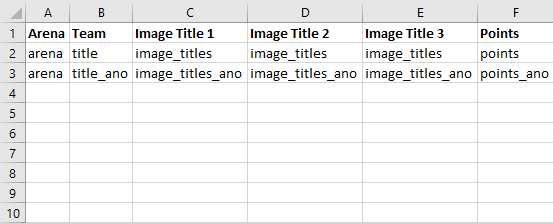
Currently I can manage to transfer my data to excel, but I can't figure out how to format my data this way. Any help would be greatly appreciated :)
CodePudding user response:
First of all, the code that you are using is not actually wholly correct. E.g.:
analyze(46275)
(('Grind', '10 pts', 'roublard, ecaflip'),
('SOLARY', '50 pts', 'enutrof, eniripsa, steamer, eliotrope'), 'A10')
Notice that the first player only has two image titles, and the second one has four. This is incorrect, and happens because your code assumes that img tags with the class ending in "dead" belong to the first player, and the ones that have a class named "class" belong to the second. This happens to be true for your first match (i.e. https://ktarena.com/fr/207-dofus-world-cup/match/46270), but very often this is not true at all. E.g. if I compare my result below with the same method applied to your analyze function, I end up with mismatches is 118 rows out of 248.
Here's a suggested rewrite:
import requests
from bs4 import BeautifulSoup
import pandas as pd
def analyze_new(i):
# You don't need `/1` at the end of the url
url = f"https://ktarena.com/fr/207-dofus-world-cup/match/{i}"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
arena = soup.find('span',class_='name').get_text()
# find all teams, and look for info inside each team
teams = soup.findAll('div',class_='team')
my_teams = [tuple()]*2
for idx, team in enumerate(teams):
my_teams[idx] = my_teams[idx] \
(team.select(".name a")[0].get_text(),)
my_teams[idx] = my_teams[idx] \
(soup.select(".result .points")[idx].get_text(),)
my_teams[idx] = my_teams[idx] \
(', '.join([img['title'] for img in team.findAll('img')[1:]]),)
# notice, we need `return` instead of `print` to use the data
return *my_teams,arena
print(analyze_new(46275))
(('Grind', '10 pts', 'roublard, ecaflip, enutrof'),
('SOLARY', '50 pts', 'eniripsa, steamer, eliotrope'), 'A10')
Before writing this data to excel, I would create a 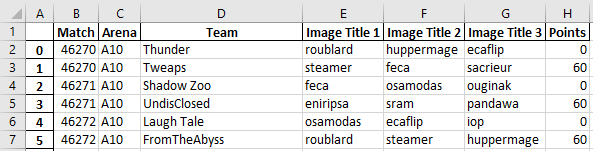
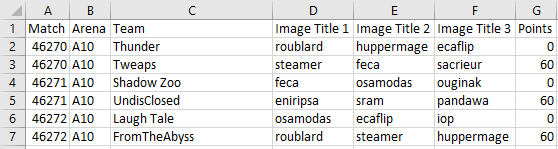
If you dislike the default styles added to the header row and index column, you can write it away like so:
df.T.reset_index().T.to_excel('test.xlsx', index=False, header=False)
Result:
Incidentally, I assume you have a particular reason for wanting the function to return the relevant data as *my_teams,arena. If not, it would be better to let the function itself do most of the heavy lifting. E.g. we could write something like this, and return a df directly.
def analyze_dict(i):
url = f"https://ktarena.com/fr/207-dofus-world-cup/match/{i}"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
d = {'Match': [i]*2,
'Arena': [soup.find('span',class_='name').get_text()]*2,
'Team': [],
'Image Title 1': [],
'Image Title 2': [],
'Image Title 3': [],
'Points': [],
}
teams = soup.findAll('div',class_='team')
for idx, team in enumerate(teams):
d['Team'].append(team.select(".name a")[0].get_text())
d['Points'].append(int(soup.select(".result .points")[idx].get_text().split(' ')[0]))
for img_idx, img in enumerate(team.findAll('img')[1:]):
d[f'Image Title {img_idx 1}'].append(img['title'])
return pd.DataFrame(d)
print(analyze_dict(46275))
Match Arena Team Image Title 1 Image Title 2 Image Title 3 Points
0 46275 A10 Grind roublard ecaflip enutrof 10
1 46275 A10 SOLARY eniripsa steamer eliotrope 50
Now, we only need to do the following outside the function:
dfs = []
for i in range(46270, 46394):
dfs.append(analyze_dict(i))
df = pd.concat(dfs, axis=0, ignore_index=True)
print(df.head())
Match Arena Team Image Title 1 Image Title 2 Image Title 3 Points
0 46270 A10 Thunder roublard huppermage ecaflip 0
1 46270 A10 Tweaps steamer feca sacrieur 60
2 46271 A10 Shadow Zoo feca osamodas ouginak 0
3 46271 A10 UndisClosed eniripsa sram pandawa 60
4 46272 A10 Laugh Tale osamodas ecaflip iop 0
CodePudding user response:
With hardly any changes from your post, you can use the openpyxl library to write the output to an excel file as shown below:
import requests
from openpyxl import Workbook
from bs4 import BeautifulSoup
def analyze(i):
url = f"https://ktarena.com/fr/207-dofus-world-cup/match/{i}/1"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
arena = soup.find("span", attrs=('name')).text
title = soup.select_one("[class='team'] .name a").text
point = soup.select(".result .points")[0].text
image_titles = image_titles = [i['title'] for i in soup.select("[class='team']:nth-of-type(1) [class^='class'] > img")]
try:
image_title_one = image_titles[0]
except IndexError: image_title_one = ""
try:
image_title_two = image_titles[1]
except IndexError: image_title_two = ""
try:
image_title_three = image_titles[2]
except IndexError: image_title_three = ""
ws.append([arena,title,image_title_one,image_title_two,image_title_three,point])
title_ano = soup.select("[class='team'] .name a")[1].text
point_ano = soup.select(".result .points")[1].text
image_titles_ano = [i['title'] for i in soup.select("[class='team']:nth-of-type(2) [class^='class'] > img")]
try:
image_title_ano_one = image_titles_ano[0]
except IndexError: image_title_ano_one = ""
try:
image_title_ano_two = image_titles_ano[1]
except IndexError: image_title_ano_two = ""
try:
image_title_ano_three = image_titles_ano[2]
except IndexError: image_title_ano_three = ""
ws.append([arena,title_ano,image_title_ano_one,image_title_ano_two,image_title_ano_three,point_ano])
print((title,point,image_titles),(title_ano,point_ano,image_titles_ano),arena)
if __name__ == '__main__':
wb = Workbook()
wb.remove(wb['Sheet'])
ws = wb.create_sheet("result")
ws.append(['Arena','Team','Image Title 1','Image Title 2','Image Title 3','Points'])
for i in range(46270, 46290):
analyze(i)
wb.save("output.xlsx")
I've fixed the selectors to grab the right number of image titles.