I have some questions about roofline model about how to deal with the point which is in memory bound.
Questions:
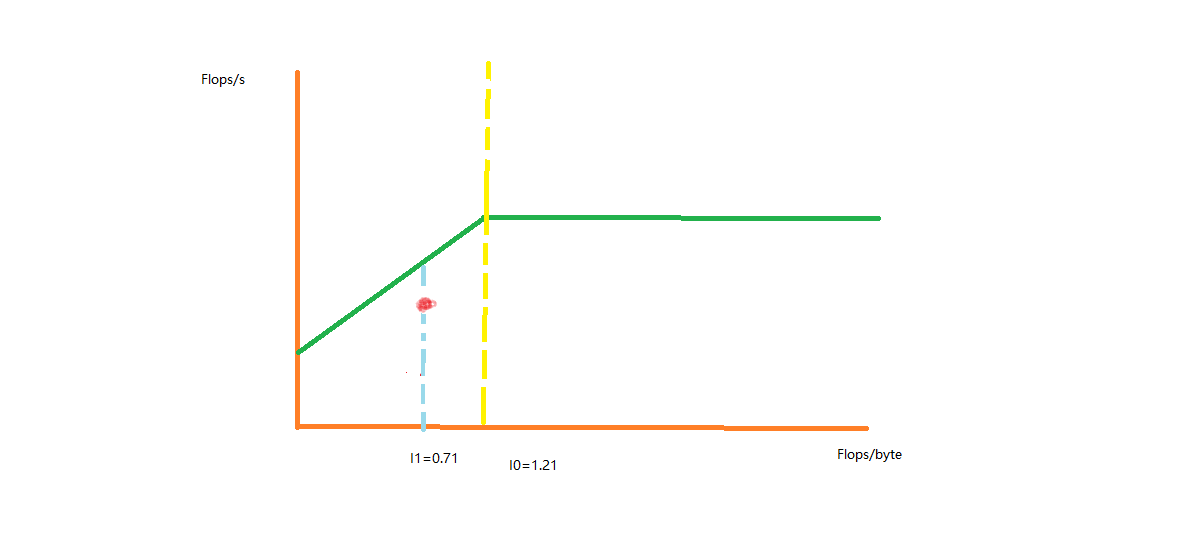
1)If the I0 derived from I0.BW=Peak is 1.21,and the actual I1 is 0.71,whether does it mean the actual I1 lies in memory bound?
2)If I1 lies in memory bound ,how could we optimize the code to get a better performance value?
3)With less data movement or more data loaded in cache?
4)If the performance value of the red point with I1=0.72 lies below the memory bound or away from memory bound , how could we optimize the code to get a better performance?
5)If the point with red color lies in the region of memory bound,whether does it mean that the memory is not fully used?But how to optimize the code to achieve a better performance?
CodePudding user response:
If the I0 derived from I0.BW=Peak is 1.21,and the actual I1 is 0.71,whether does it mean the actual I1 lies in memory bound?
I0 is a point where the computation is both saturating the memory and saturating the CPU. This is very unusual in practice since saturating one of the two generally slow down a bit the other. This is especially true for the memory: reads tends to cause stalls preventing the CPU from executing arithmetic operations hence reducing the FLOPS compared to the peak FLOPS.
I1 is a point where the computation is memory bound indeed.
Overall, the left part before the yellow line is memory bound.
If I1 lies in memory bound ,how could we optimize the code to get a better performance value?
You should perform memory-related optimizations in this case. The first thing to check/optimize is the memory access pattern: you should read data contiguously as much as possible. Then, you should avoid reading/writing many huge dataset and compute data on-the-fly and in-place. In practice, this means merging loops of different algorithms so not to read data written just previously. Tiling can help when the access pattern is not the same between multiple algorithms.
With less data movement or more data loaded in cache?
Yes, less data movement will definitively help. In this case, the access pattern is certainly the biggest issue. Having data in the cache can help too if possible (especially when memory is not read/written contiguously and cannot be for the target algorithm). Sometimes, it is worth using a much more computationally intensive algorithm that performs significantly better in memory (eg. better access pattern) since memory is slow and the gap between the CPU speed and memory speed is not plan to be smaller any time soon (quite the opposite in fact, this is called the "Memory Wall").
If the performance value of the red point with I1=0.72 lies below the memory bound or away from memory bound , how could we optimize the code to get a better performance?
There are different level of memory bound codes. For example a code can be bound by the RAM speed of one NUMA node. It can be bound by the RAM speed of all NUMA node combined. It can be bound by the L3 cache (which is generally much faster than the main RAM). It can also be bound by the L2 cache. It is a bit hard to say which one it is in practice. One issue of the roofline model is that a point is draw from only two metrics that are average values got from a given code. In practice the code can be split a computing part doing RAM-bound operation and an arithmetic-bound one. The result will be averaged and results will be hard to interpret. More information are required to understand what is going on. Performance counters can help for that.
Overall, I advise you to profile more deeply what is going on and apply mainly memory-related optimization (see above) so to move the red point on the right part of the graph. Then, later, you can optimize the computation so to move the point upper.
If the point with red color lies in the region of memory bound,whether does it mean that the memory is not fully used?
Basically, yes, but the meaning of "memory" is not well defined enough here (see above). This is why a deeper analysis is required. I advise you to measure the L3 throughput and the one of the RAM. If you run your code on a NUMA platform, then I advise you to run your code on only 1 NUMA node first, so to understand what is going on in a simpler case. If the code only behave poorly with multiple NUMA node, you can then know that you need to perform NUMA-related optimizations (eg. taking care of the allocation policy and the first-touch).
Overall, a FLOPS/byte of ~1 is small. Codes are generally still memory bound even with a FLOPS/byte ~10 on most platforms (15-30 is typically the limit where a code becomes compute-bound).