Apologies for the unclear title. Although not effective, I couldn't think of a better way to describe this problem.
Here is a sample dataset I am working with
test = data.frame(
Value = c(1:5, 5:1),
Index = c(1:5, 1:5),
GroupNum = c(rep.int(1, 5), rep.int(2, 5))
)
I want to create a new column (called "Value_Standardized") whose values are calculated by grouping the data by GroupNum and then dividing each Value observation by the Value observation of the group when the Index is 1.
Here's what I've come up with so far.
test2 = test %>%
group_by(GroupNum) %>%
mutate(Value_Standardized = Value / special_function(Value))
The special_function would represent a way to get value when Index == 1.
That is also precisely the problem - I cannot figure out a way to get the denominator to be the value when index == 1 in that group. Unfortunately, the value when the index is 1 is not necessarily the max or the min of the group.
Thanks in advance.
Edit: Emphasis added for clarity.
CodePudding user response:
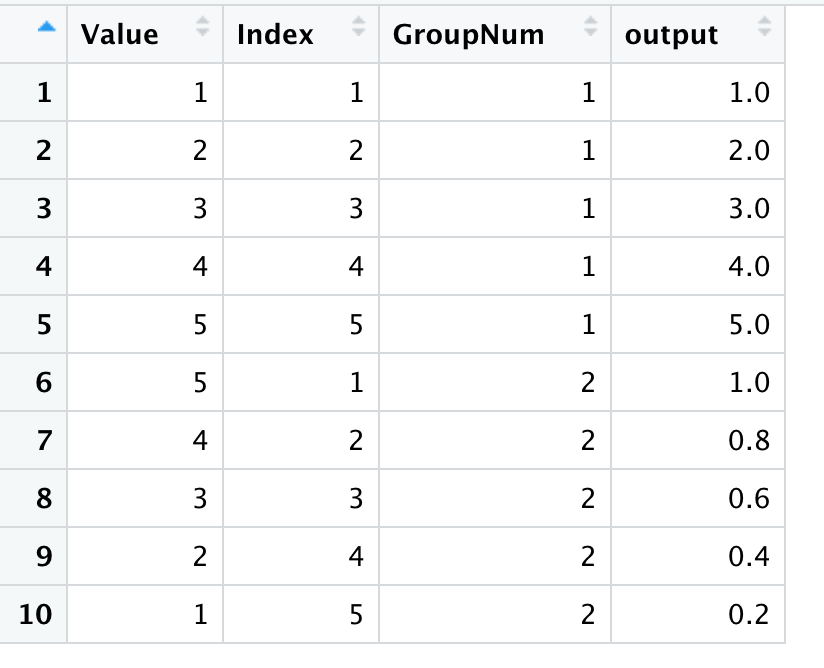
There is a super simple tidyverse way of doing this with the method cur_data() it pulls the tibble for the current subset (group) of data and acts on it
test2 <- test %>%
group_by(GroupNum) %>%
mutate(output=Value/cur_data()$Value[1])
 The
The cur_data() grabs the tibble, then you extract the Values column as you would normally using $Value and because the denominator is always the first row in this group, you just specify that index with [1]
Nice and neat, there are a whole bunch of cur_... methods you can use, check them out here:
CodePudding user response:
Not sure if this is what you meant, nor if it's the best way to do this but...
Instead of using a group_by I used a nested pipe, filtering and then left_joining the table to itself.
test = data.frame(
Value = c(1:5, 5:1),
Index = c(1:5, 1:5),
GroupNum = c(rep.int(1, 5), rep.int(2, 5))
)
test %>%
left_join(test %>%
filter(Index == 1) %>%
select(Value,GroupNum),
by = "GroupNum",
suffix = c('','_Index_1')) %>%
mutate(Value = Value/Value_Index_1)
output:
Value Index GroupNum Value_Index_1
1 1.0 1 1 1
2 2.0 2 1 1
3 3.0 3 1 1
4 4.0 4 1 1
5 5.0 5 1 1
6 1.0 1 2 5
7 0.8 2 2 5
8 0.6 3 2 5
9 0.4 4 2 5
10 0.2 5 2 5
CodePudding user response:
A quick base R solution:
test = data.frame(
Value = c(1:5, 5:1),
Index = c(1:5, 1:5),
GroupNum = c(rep.int(1, 5), rep.int(2, 5)),
Value_Standardized = NA
)
groups <- levels(factor(test$GroupNum))
for(currentGroup in groups) {
test$Value_Standardized[test$GroupNum == currentGroup] <- test$Value[test$GroupNum == currentGroup] / test$Value[test$GroupNum == currentGroup & test$Index == 1]
}
This only works under the assumption that each group will have only one observation with a "1" index though. It's easy to run into trouble...