My dataset follows this structure:
Column1 Column2 Column3 Categories
20 0 21 Category1
18 1 21 Category1
18 0 28 Category1
21 2 27 Category1
21 2 27 Category1
21 2 23 Category1
28 2 23 Category1
27 1 39 Category1
23 2 21 Category1
23 2 21 Category1
27 0 33 Category2
23 1 23 Category2
23 2 4 Category2
39 2 6 Category2
21 1 9 Category2
25 1 77 Category2
25 5 49 Category2
23 4 21 Category2
18 2 2 Category2
22 1 33 Category2
21 1 55 Category3
29 1 54 Category3
29 2 8 Category3
24 2 9 Category3
24 1 23 Category3
22 0 40 Category3
21 1 39 Category3
21 0 12 Category3
27 1 22 Category3
18 3 27 Category3
I aim to test residuals of lm(Column1 ~ Column2) ~ Column3, according Categories:
regression <- by(data, data$Categories, function(x) summary(lm(resid(lm(Columns1 ~ Columns2)) ~ Columns3, data = x)))
regression
How can I plot resid(lm(Columns1 ~ Columns2)) ~ Columns3 according Categories with ggplot2, using facet_wrap? (or without ggplot?). Thanks for any help!
CodePudding user response:
You can just add the residuals as a column to your data frame, then you can plot residuals by any column you want. If you wanna test the differences in residuals over the categories, you can plot bars with error bars, for example.
Ex.:
library(tidyverse)
set.seed(1)
df = data.frame(
Column1 = sample(15:50, 30, replace = TRUE),
Column2 = sample(0:1, 30, replace = TRUE, prob = c(.6,.4)),
Column3 = sample(5:50, 30, replace = TRUE),
Categories = sample(c("Category1", "Category2", "Category3"), 30, replace = TRUE)
)
mod1 = lm(Column1 ~ Column2, df)
df$residuals = mod1$residuals
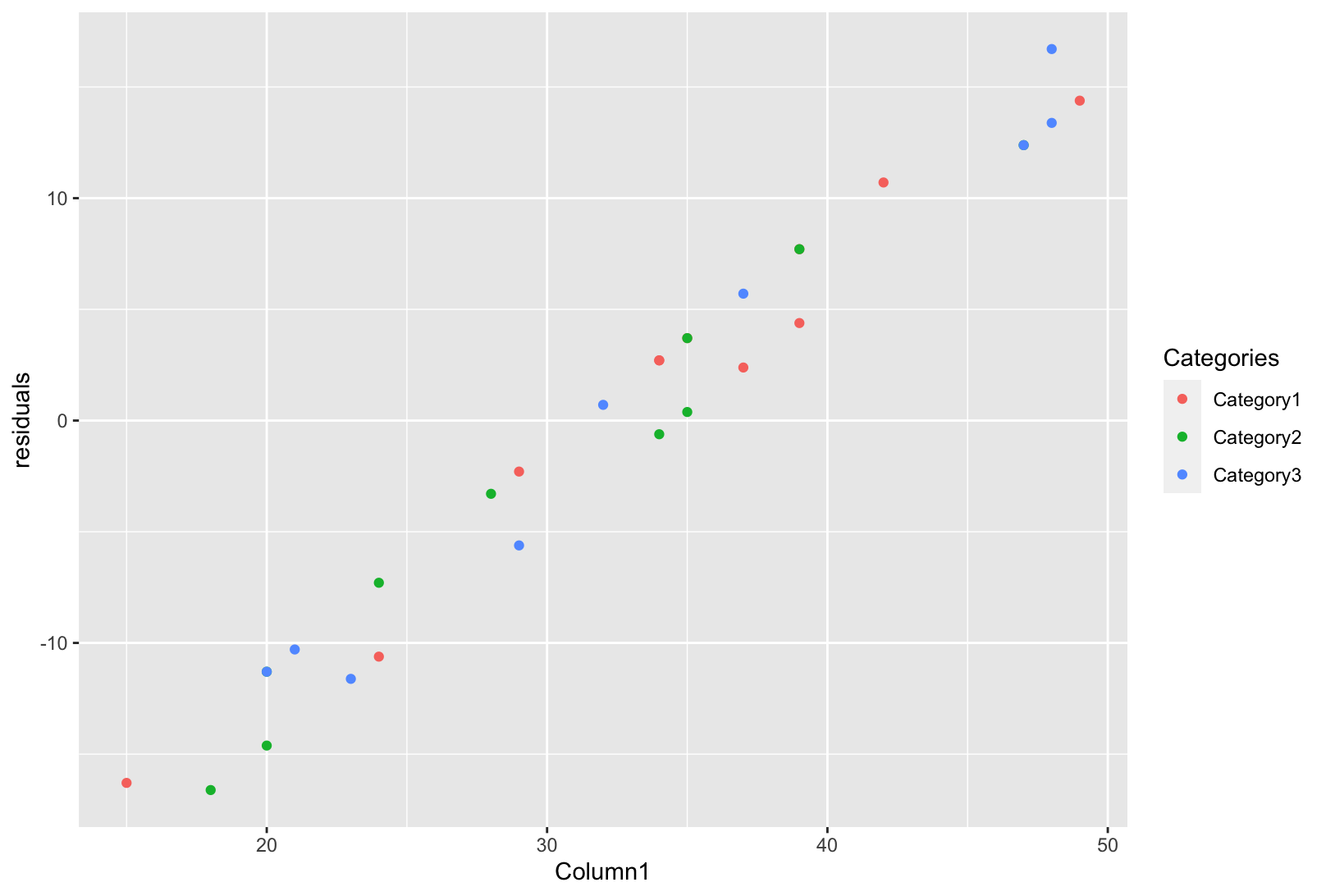
df |> ggplot(aes(x = Column1, y = residuals, color = Categories))
geom_point()