I have to make some SQL query. I'll only put here tables and results I need - I am sure this is the best way for a clear explanation (at the bottom of the question I provided SQL queries for database filling).
- short description:
TASK: After full join concatenation I receive a result where (for example) tableA.point column (that is used in the SELECT statement) in some cells returns NULL. In these cases, I need to change tableA.point column to the tableB.point (from the joined table).
So, tables:
(Columns point date are composite key.)
- outcome_o:
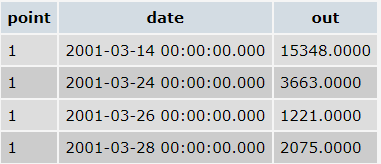
- income_o:
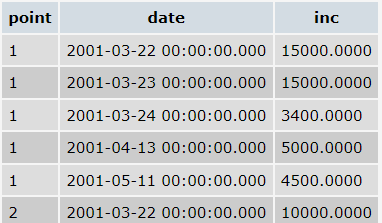
- The result I need an example (we can see - I need a concatenated table with both
outandinccolumns in rows)
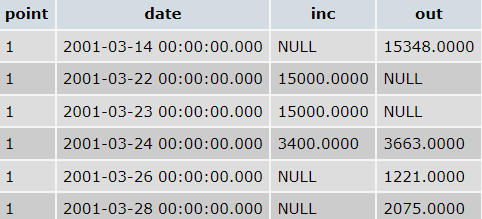
My attempt:
SELECT outcome_o.point,
outcome_o.date,
inc,
out
FROM income_o
FULL JOIN outcome_o ON income_o.point = outcome_o.point AND income_o.date = outcome_o.date
The result is the same as I need, except NULL in different point and date columns:
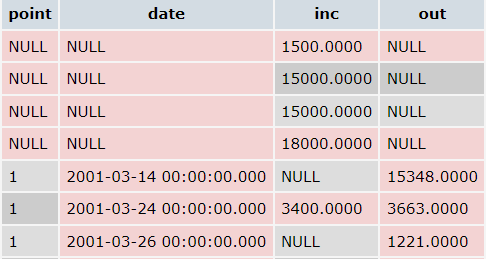
I tried to avoid this with CASE statement:
SELECT
CASE outcome_o.point
WHEN NULL
THEN income_o.point
ELSE outcome_o.point
END as point,
....
But this not works as I imagined (all cells became NULL in point column).
Could anyone help me with this solution? I know there is I have to use JOIN, CASE (case-mandatory) and possibly UNION commands.
Thanks
Tables creation:
CREATE TABLE income(
point INT,
date VARCHAR(60),
inc FLOAT
)
CREATE TABLE outcome(
point INT,
date VARCHAR(60),
ou_t FLOAT
)
INSERT INTO income VALUES
(1, '2001-03-22', 15000.0000),
(1, '2001-03-23', 15000.0000),
(1, '2001-03-24', 3400.0000),
(1, '2001-04-13', 5000.0000),
(1, '2001-05-11', 4500.0000),
(2, '2001-03-22', 10000.0000),
(2, '2001-03-24', 1500.0000),
(3, '2001-09-13', 11500.0000),
(3, '2001-10-02', 18000.0000);
INSERT INTO outcome VALUES
(1, '2001-03-14 00:00:00.000', 15348.0000),
(1, '2001-03-24 00:00:00.000', 3663.0000),
(1, '2001-03-26 00:00:00.000', 1221.0000),
(1, '2001-03-28 00:00:00.000', 2075.0000),
(1, '2001-03-29 00:00:00.000', 2004.0000),
(1, '2001-04-11 00:00:00.000', 3195.0400),
(1, '2001-04-13 00:00:00.000', 4490.0000),
(1, '2001-04-27 00:00:00.000', 3110.0000),
(1, '2001-05-11 00:00:00.000', 2530.0000),
(2, '2001-03-22 00:00:00.000', 1440.0000),
(2, '2001-03-29 00:00:00.000', 7848.0000),
(2, '2001-04-02 00:00:00.000', 2040.0000),
(3, '2001-09-13 00:00:00.000', 1500.0000),
(3, '2001-09-14 00:00:00.000', 2300.0000),
(3, '2002-09-16 00:00:00.000', 2150.0000);
CodePudding user response:
The first step is to create a date range reference table. To do that, we can use Common Table Expression (cte):
WITH RECURSIVE cte AS (
SELECT Min(mndate) mindt, MAX(mxdate) maxdt
FROM (SELECT MIN(date) AS mndate, MAX(date) AS mxdate
FROM outcome
UNION
SELECT MIN(date), MAX(date)
FROM income) v
UNION
SELECT mindt INTERVAL 1 DAY, maxdt
FROM cte
WHERE mindt INTERVAL 1 DAY <= maxdt)
SELECT mindt
FROM cte
Here I'm trying to generate the dynamic date range based on the minimum & maximum date value from both of your tables. This is particularly useful when you don't to keep on changing the date range but if you don't mind, you can just generate them simply like so:
WITH RECURSIVE cte AS (
SELECT '2001-03-14 00:00:00' dt
UNION
SELECT dt INTERVAL 1 DAY
FROM cte
WHERE dt INTERVAL 1 DAY <= '2002-09-16')
SELECT mindt
FROM cte
From here, I'll do a CROSS JOIN to get the distinct point value from both tables:
...
CROSS JOIN (SELECT DISTINCT point FROM outcome
UNION
SELECT DISTINCT point FROM income) p
Now we have a reference table with all the point and date range. Let's wrap those in another cte.
WITH RECURSIVE cte AS (
SELECT Min(mndate) mindt, MAX(mxdate) maxdt
FROM (SELECT MIN(date) AS mndate, MAX(date) AS mxdate
FROM outcome
UNION
SELECT MIN(date), MAX(date)
FROM income) v
UNION
SELECT mindt INTERVAL 1 DAY, maxdt
FROM cte
WHERE mindt INTERVAL 1 DAY <= maxdt),
cte2 AS (
SELECT point, mindt
FROM cte
CROSS JOIN (SELECT DISTINCT point FROM outcome
UNION
SELECT DISTINCT point FROM income) p)
SELECT *
FROM cte2;
Next step is taking your current query attempt and LEFT JOIN it to the reference table:
WITH RECURSIVE cte AS (
SELECT Min(mndate) mindt, MAX(mxdate) maxdt
FROM (SELECT MIN(date) AS mndate, MAX(date) AS mxdate
FROM outcome
UNION
SELECT MIN(date), MAX(date)
FROM income) v
UNION
SELECT mindt INTERVAL 1 DAY, maxdt
FROM cte
WHERE mindt INTERVAL 1 DAY <= maxdt),
cte2 AS (
SELECT point, CAST(mindt AS DATE) AS rdate
FROM cte
CROSS JOIN (SELECT DISTINCT point FROM outcome
UNION
SELECT DISTINCT point FROM income) p)
SELECT *
FROM cte2
LEFT JOIN outcome
ON cte2.point=outcome.point
AND cte2.rdate=outcome.date
LEFT JOIN income
ON cte2.point=income.point
AND cte2.rdate=income.date
/*added conditions*/
WHERE cte2.point=1
AND COALESCE(outcome.date, income.date) IS NOT NULL
/*****/
ORDER BY cte2.rdate;
I noticed that your date column is using VARCHAR() datatype instead of DATE or DATETIME. Which is why my initial test return only one result. However, I do notice that if I compare YYYY-MM-DD format against your table date value, it returns other results, which is why I did CAST(mindt AS DATE) AS rdate in cte2. I do recommend that you change the date column to MySQL standard date format though.
You probably find the query a bit too long but if you have a table where you store dates or as we call it calendar table, the query will be much shorter, perhaps like this:
SELECT *
FROM calendar
LEFT JOIN outcome
ON calendar.point=outcome.point
AND calendar.rdate=outcome.date
LEFT JOIN income
ON calendar.point=income.point
AND calendar.rdate=income.date
/*added conditions*/
WHERE calendar.point=1
AND COALESCE(outcome.date, income.date) IS NOT NULL
/*****/
ORDER BY calendar.rdate;
CodePudding user response:
It seems I was using the wrong syntax for the solution. So, as I found out, dynamically column selection is accessible in the SELECT query:
- correct
CASEstatement:
(
CASE
WHEN outcome_o.point IS NULL
THEN income_o.point
ELSE outcome_o.point
END
) as point,
In this case query selects joined table column in the case the main table column is NULL.
- Full query (returns result exactly I need):
SELECT
(
CASE
WHEN outcome_o.point IS NULL
THEN income_o.point
ELSE outcome_o.point
END
) as point,
(
CASE
WHEN outcome_o.date IS NULL
THEN income_o.date
ELSE outcome_o.date
END
) as date,
inc,
out
FROM income_o
FULL JOIN outcome_o ON income_o.point = outcome_o.point AND income_o.date = outcome_o.date